共計 3008 個字符,預計需要花費 8 分鐘才能閱讀完成。
自動寫代碼機器人,免費開通
丸趣 TV 小編給大家分享一下 MongoDB 分片鍵的示例分析,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
MongoDB 版本:3.6
一、分片鍵類別
1. 升序片鍵
升序片鍵例如:日期時間字段、自增字段。
2. 隨機分發片鍵
隨機分發片鍵例如:用戶名、郵件名、UUID、MD5 值或者是其它的一些沒有規律的值的列。
3. 基于位置的片鍵
基于位置的片鍵例如:IP、經緯度、居住地址等。
二、分片策略
1. 范圍分片
創建分片時,只在主分片上創建了一個塊{username : { $minKey : 1} } — {username : { $maxKey : 1} } on : rs-a Timestamp(1, 0)。

至少得 3 個不同的值才會進行塊切分,相同的值只會在一個分片塊中。比如對一個 name 字段進行范圍分區,如果一直往 name 字段插入 a,那么它會一直存儲主分片的 {username : { $minKey : 1} } — {username : { $maxKey : 1} } 中,直到 name 出現三個不同的值,比如“a”,“b”,“c”這個時候就會進行分片。當然這只是測試,現實中不會對這種粗粒度的字段單獨做分片。
2.hashed 分片
創建分片時,默認在每個分片上創建了兩個數據塊。但是當前每個塊上面是沒有數據的。

3. 組合分片
組合分片是比較好的一種分片的選擇,好的組合分片可以同時解決熱點和隨機讀 IO 問題。例如:
sh.shardCollection(test.bbbb ,{ username :1, _id :1});4. 標簽分片
比如對于一些日志非查詢文檔,可以通過標簽將其只插入到某個分片中。例如
sh.addTagRange(test.log ,{ _id : { $minKey : 1 } }, { _id : { $maxKey : 1 } }, tag_rs-a可以在 config 庫中的 tag 文檔中查看設置的標簽信息。
use config
db.tags.find();
三、標簽
可以通過標簽將特定范圍的數據在指定的分片中。

將 {_id : 18000} — {_id : 26000} 范圍的數據保存到 rs- a 的分片上,這部分數據跨越了兩個數據塊。
1. 為分片指定 tag
sh.addShardTag( rs-a , tag_rs-a
sh.addShardTag( rs-b , tag_rs-b
sh.addShardTag(rs-c , tag_rs-c
2. 創建規則
sh.addTagRange(test.person ,{ _id : 18000 }, { _id : 26000 }, tag_rs-a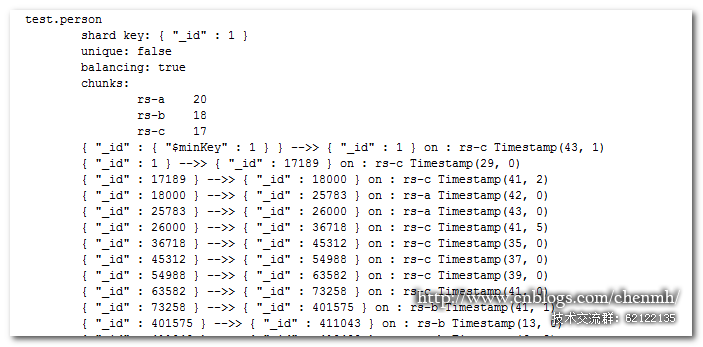
數據 {_id : 18000} — {_id : 26000} 已經被移動到了 rs- a 分片上。
四、分片案例
分片策略沒有絕對的好壞,針對不同的業務場景選擇不同的分片策略。
1. 分片情景
1. 所有的分片讀寫都均勻。
2. 數據訪問均勻,而不是隨機性的訪問;由于新數據都是先在內存中創建,盡量避免需要從磁盤訪問新數據。
3. 盡量避免由于數據塊的數據移動導致數據從磁盤加載到內存中從而導致熱數據被清理出內存。
4. 組合字段分片可能會是理想的分片方案。

分片鍵公式:{coarseLocality:1,search:1}
coarseLocality:應該是一個大粒度的局部字段。比如 MONTH 月份升序字段。
search: 是一個經常用來查找的字段。
2. 分片案例
案例 1. 使用日期字段、自增字段、時間戳分片的問題
有一個網站瀏覽記錄表,表中有一個 createtime 字段用來記錄每天記錄的插入時間。
對于這類文檔不太適合使用 createtime 字段作為分片字段,因為讀寫可能都會集中在最新的分片上。使用自增字段也存在同樣的問題
案例 2. 大粒度字段分片問題
有一個五大洲的用戶文檔表,表中有一個 continent 字段存儲用戶所在洲。
如果使用 continent 作為分片字段會存在以下幾個問題:
1. 分片的粒度太大了,會導致最后每一個分片的數據都非常的大而且沒有再分的可能。而且也有可能會導致磁盤空間不夠的情況。
2. 可能會導致某個分片在某個時間點的訪問量遠遠大于其他分片。
案例 3:使用月份和用戶名進行組合分片
有一個用戶操作記錄集合,業務需要查詢用戶最近一個月操作記錄。集合有 month,userName 鍵
使用 {month:1,userName:1} 分片情景如下:
month 保證熱數據優于內存。
userName: 保證數據的隨機性,避免集中過熱問題。
存在的問題:對于新文檔由于很多月份還不存在,會導致新數據都是往最后一個分片上面插入數據,存在熱讀寫問題,最后通過均衡器對數據塊進行移動。
數據測試
sh.shardCollection(test.news ,{ month :1, username :1});
—- 插入 1 月數據 10 萬記錄
for(var i=0;i 100000;i++){db.news.insert({ _id :i, month : 1 , username :Math.random(), createdate :new Date()})}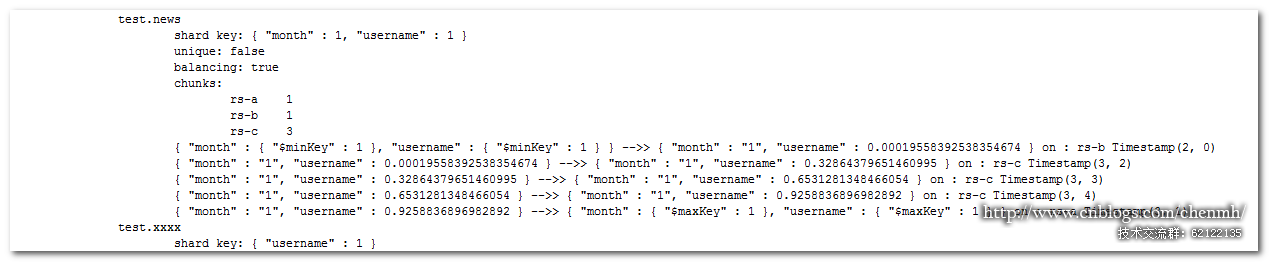
—- 插入 2 月數據 10 萬記錄
for(var i=100000;i 200000;i++){ db.news.insert({ _id :i, month : 2 , username :Math.random(), createdate :new Date()})}新數據往一直往最末尾的分片(rs-a)上插,因為這個時候 month :2 在最大的分片上。{month : 1 , username : 0.9258836896982892} — {month : { $maxKey : 1}, username : {$maxKey : 1} } on : rs-a Timestamp(3, 1)

數據插入完之后均衡器將 rs- c 上的一個塊分給了 rs-a
—- 插入全部月份數據。
for(var a=1;a a++)
for(var i=0;i 20000;i++){ db.news.insert({ month :a, username :Math.random(), createdate :new Date()})}
}

保證每個月的數據都均勻的分布到不同的分片上,并且隨著時間的推移舊的數據可能就不會被使用也不會被移動。
注意:這個案例比較特殊,因為對于日志集合比較舊的數據基本上是不會被查詢的,所以借助了 month 鍵作為了分片鍵保證了熱數據優先存儲于內存,對于整張表都是熱數據比如登入用戶集合就不適合這種分片方式,hashed 會更適合。
案例 4:使用隊列
隊列不僅在容災中非常的有用,而且在常規的突發流量下也非常的有用。隊列可以吸收短時間內爆發的大量請求。也可以把隊列反過來用,即緩存 MongoDB 返回的結果。
比如:RabbitMQ
案例 5:使用用戶名和創建時間進行組合分片
用戶名:保證數據的隨機性,避免熱點問題
創建時間:保證單個數據塊過大問題
五、設計集合注意事項
1. 集合的鍵數量應該是固定的,包括嵌套文檔的數量都應該提前規劃好。
2. 盡量都是做原子更新,而不是某個鍵的值受其它鍵值更新的影響。比如 num1,num2,total 如果 num 鍵的值是經常會被更新的那么這種設計就不好,因為 total 也要對應跟著變,而 mongodb 本身計算能力就很弱。
看完了這篇文章,相信你對“MongoDB 分片鍵的示例分析”有了一定的了解,如果想了解更多相關知識,歡迎關注丸趣 TV 行業資訊頻道,感謝各位的閱讀!
向 AI 問一下細節










