共計 2562 個字符,預計需要花費 7 分鐘才能閱讀完成。
自動寫代碼機器人,免費開通
這篇文章主要介紹“如何快速完成 mysql 數據遷移”,在日常操作中,相信很多人在如何快速完成 mysql 數據遷移問題上存在疑惑,丸趣 TV 小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”如何快速完成 mysql 數據遷移”的疑惑有所幫助!接下來,請跟著丸趣 TV 小編一起來學習吧!
背景
上個月跟朋友一起做了個微信小程序,趁著 5.20 節日的熱度,兩個禮拜內迅速積累了一百多萬用戶,我們在小程序頁面增加了收集 formid 的埋點,用于給微信用戶發送模板消息通知。
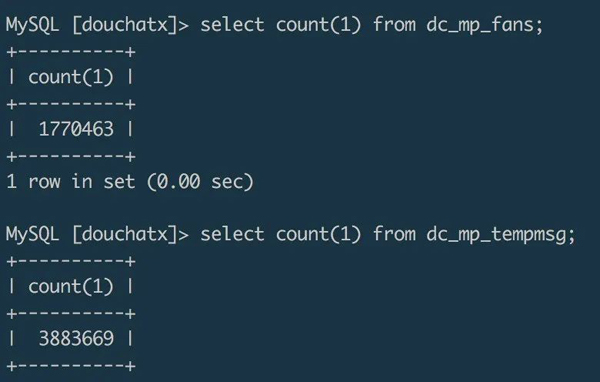
這個小程序一開始的后端邏輯是用 douchat 框架寫的,使用框架自帶的 dc_mp_fans 表存儲微信端授權登錄的用戶信息,使用 dc_mp_tempmsg 表存儲 formid。截止到目前,收集到的數據超過 380 萬,很大一部分 formid 都已經成功使用給用戶發送過模板通知,起到了較好的二次推廣的效果。
隨著數據量的增大,之前使用的服務器空間開始有點不夠用,最近新寫了一個專門用于做小程序后臺開發的框架,于是想把原來的數據遷移到新系統的數據庫。買了一臺 4 核 8G 的機器,開始做數據遷移。下面對遷移過程做一個簡單的記錄。
img
方案選擇
mysqldump 遷移
平常開發中,我們比較經常使用的數據備份遷移方式是用 mysqldump 工具導出一個 sql 文件,再在新數據庫中導入 sql 來完成數據遷移。試驗發現,通過 mysqldump 導出百萬級量的數據庫成一個 sql 文件,大概耗時幾分鐘,導出的 sql 文件大小在 1G 左右,然后再把這個 1G 的 sql 文件通過 scp 命令復制到另一臺服務器,大概也需要耗時幾分鐘。在新服務器的數據庫中通過 source 命令來導入數據,我跑了一晚上都沒有把數據導入進來,cpu 跑滿。
腳本遷移
直接通過命令行操作數據庫進行數據的導出和導入是比較便捷的方式,但是數據量較大的情況下往往會比較耗時,對服務器性能要求也比較高。如果對數據遷移時間要求不是很高,可以嘗試寫腳本來遷移數據。雖然沒有實際嘗試,但是我想過大概有兩種腳本方案。
第一種方式,在遷移目標服務器跑一個遷移腳本,遠程連接源數據服務器的數據庫,通過設置查詢條件,分塊讀取源數據,并在讀取完之后寫入目標數據庫。這種遷移方式效率可能會比較低,數據導出和導入相當于是一個同步的過程,需要等到讀取完了才能寫入。如果查詢條件設計得合理,也可以通過多線程的方式啟動多個遷移腳本,達到并行遷移的效果。
第二種方式,可以結合 redis 搭建一個“生產 + 消費”的遷移方案。源數據服務器可以作為數據生產者,在源數據服務器上跑一個多線程腳本,并行讀取數據庫里面的數據,并把數據寫入到 redis 隊列。目標服務器作為一個消費者,在目標服務器上也跑一個多線程腳本,遠程連接 redis,并行讀取 redis 隊列里面的數據,并把讀取到的數據寫入到目標數據庫。這種方式相對于第一種方式,是一種異步方案,數據導入和數據導出可以同時進行,通過 redis 做數據的中轉站,效率會有較大的提升。
可以使用 go 語言來寫遷移腳本,利用其原生的并發特性,可以達到并行遷移數據的目的,提升遷移效率。
文件遷移
第一種遷移方案效率太低,第二種遷移方案編碼代價較高,通過對比和在網上找的資料分析,我最終選擇了通過 mysql 的 select data into outfile file.txt、load data infile file.txt into table 的命令,以導入導出文件的形式完成了百萬級數據的遷移。
遷移過程
在源數據庫中導出數據文件
select * from dc_mp_fans into outfile /data/fans.txt復制數據文件到目標服務器
zip fans.zip /data/fans.txtscp fans.zip root@ip:/data/在目標數據庫導入文件
unzip /data/fans.zip load data infile /data/fans.txt into table wxa_fans(id,appid,openid,unionid,@dummy,created_at,@dummy,nickname,gender,avatar_url,@dummy,@dummy,@dummy,@dummy,language,country,province,city,@dummy,@dummy,@dummy,@dummy,@dummy,@dummy,@dummy,@dummy,@dummy);按照這么幾個步驟操作,幾分鐘內就完成了一個百萬級數據表的跨服務器遷移工作。
注意項
mysql 安全項設置
在 mysql 執行 load data infile 和 into outfile 命令都需要在 mysql 開啟了 secure_file_priv 選項,可以通過 show global variables like %secure% 查看 mysql 是否開啟了此選項,默認值 Null 標識不允許執行導入導出命令。通過 vim /etc/my.cnf 修改 mysql 配置項,將 secure_file_priv 的值設置為空:
[mysqld] secure_file_priv=則可通過命令導入導出數據文件。
導入導出的數據表字段不對應
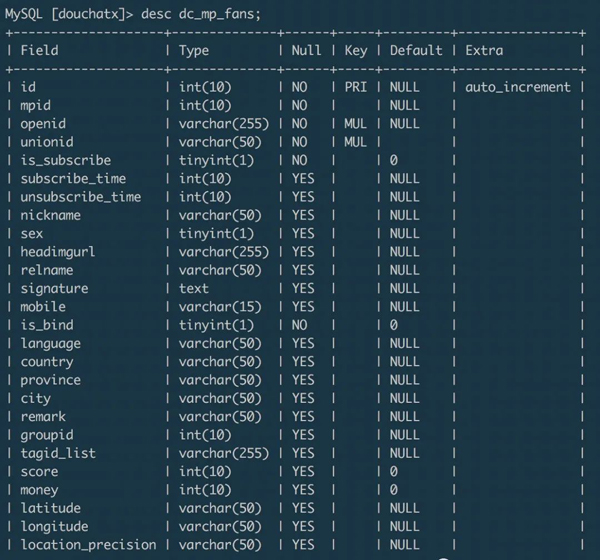
上面示例的從源數據庫的 dc_mp_fans 表遷移數據到目標數據庫的 wxa_fans 表,兩個數據表的字段分別為:- dc_mp_fans
img
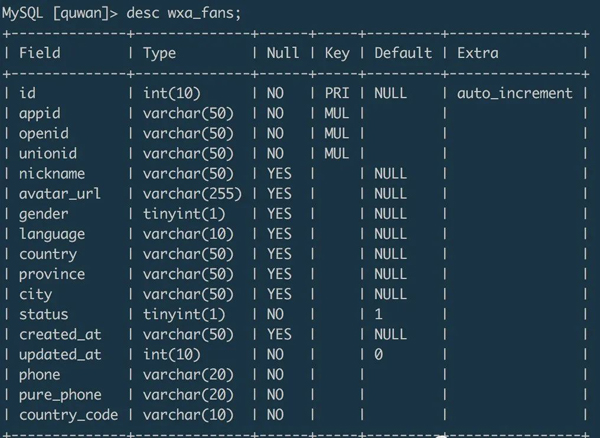
wxa_fans
img
在導入數據的時候,可以通過設置字段名來匹配目標字段的數據,可以通過 @dummy 丟棄掉不需要的目標字段數據。
總結
結合本次數據遷移經歷,總結起來就是:小數據量可以使用 mysqldump 命令進行導入導出,這種方式簡單便捷。- 數據量較大,且有足夠的遷移耐心時,可以選擇自己寫腳本,選擇合適的并行方案遷移數據,這種方式編碼成本較高。- 數據量較大,且希望能在短時間內完成數據遷移時,可以通過 mysql 導入導出文件的方式來遷移,這種方式效率較高。
到此,關于“如何快速完成 mysql 數據遷移”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注丸趣 TV 網站,丸趣 TV 小編會繼續努力為大家帶來更多實用的文章!
向 AI 問一下細節










