共計 3307 個字符,預計需要花費 9 分鐘才能閱讀完成。
自動寫代碼機器人,免費開通
MySQL 中怎么實現主從同步機制,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
最直觀的表現為:
mysql show slave status\G;
// 狀態一
Seconds_Behind_Master: NULL
// 狀態二
Seconds_Behind_Master: 0
// 狀態三
Seconds_Behind_Master: 79連續查詢,大部分時間該屬性值 =0,偶發性出現 Null 或者 79 等延時值。導致觀察主從同步延時的監控持續報警。
故障原因及解決方案
多臺備機的 server-id 一致,導致主機無法長時間同某一臺備機連接,進而無法正常同步。
修改 server-id 后,重啟數據庫恢復。
主從同步機制
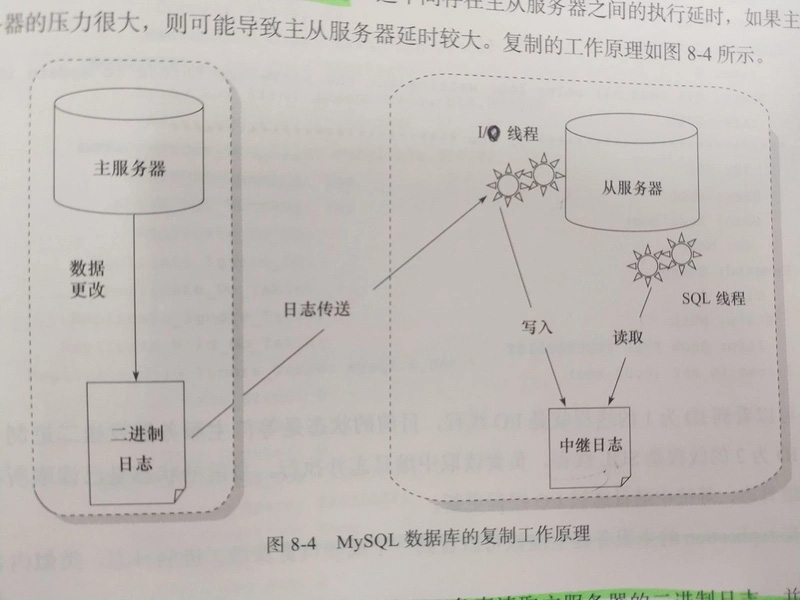
MySQL 的主從同步,又稱為復制(replication),是一種內置的高可用高性能集群解決方案,主要功能有:
數據分布:同步不需要很大帶寬,可以實現多數據中心復制數據。
讀取的負載均衡:通過服務器集群,可以通過 DNS 輪詢、Linux LVS 等 GSLB(全局負載均衡)方式,降低主服務器的讀壓力。
數據庫備份:復制是備份的一部分,但并不能代替備份。還需要與快照相結合。
高可用性和故障轉移:從服務器可以快速切換為主服務器,減少故障的停機時間和恢復時間。
主從同步分為 3 步:
主服務器(master)把數據更改記錄到二進制日志(binlog)中。
從服務器(slave)把主服務器的二進制日志復制到自己的中繼日志(relay log)中。
從服務器重做中繼日志中的日志,把更改應用到自己的數據庫上,達到數據的一致性。
主從同步是一個異步實時的同步,會實時的傳輸,但存在執行上的延時,如果主服務器壓力很大,延時也會相應擴大。
通過上面的圖,可以看到一共需要 3 個線程:
主服務器的日志傳送線程:負責將二進制日志增量傳送到備機
從服務器的 I / O 線程:負責讀取主服務器的二進制日志,并保存為中繼日志
從服務器的 SQL 線程,負責執行中繼日志
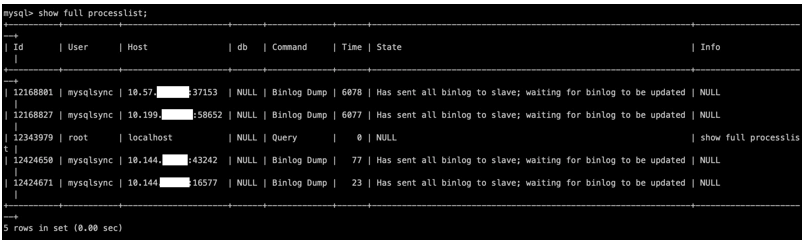
查看 MySQL 線程
我們可以使用 show full processlist; 命令來查看 MySQL 的狀態:
主機的狀態:
備機的狀態:

可以看到,我的集群架構為 1 臺主機、4 臺備機,所以在主機中有 4 個同步線程(已經發送所有的 binlog 數據到備機,等待 binlog 日志更新),1 個查看命令線程(show full processlist)。在備機中有 1 個查看命令線程,1 個 I / O 線程(等待主機發送同步數據事件),1 個 SQL 線程(已經讀取了所有中繼日志,等待 I / O 線程來更新它)。
查看同步狀態
因為主從同步是異步實時的,也就是會存在延時的情況,我們可以通過 show slave status; 來查看備機上的同步延時:
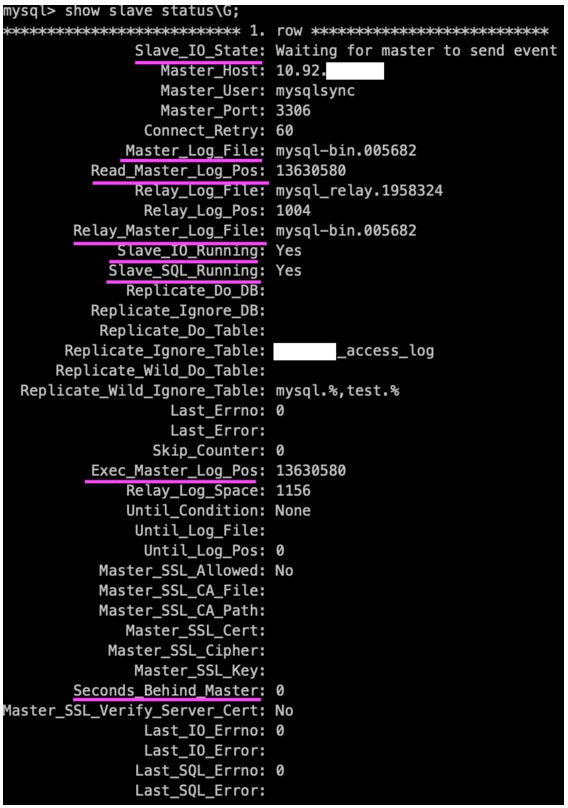
在主從同步中我們需要關注的一些屬性,已經給大家標紅了:
Slave_IO_State: 當前 I / O 線程的狀態
Master_Log_File: 當前同步的主服務器的二進制文件
Read_Master_Log_Pos: 當前同步的主服務器的二進制文件的偏移量,單位為字節,如圖中為已經同步了 12.9M(13630580/1024/1024) 的內容
Relay_Master_Log_File: 當前中繼日志同步的二進制文件
Slave_IO_Running: 從服務器中 I / O 線程的運行狀態,YES 為運行正常
Slave_SQL_Running: 從服務器中 SQL 線程的運行狀態,YES 為運行正常
Exec_Master_Log_Pos: 表示同步完成的主服務器的二進制日志偏移量
Seconds_Behind_Master: 表示從服務器數據比主服務器落后的持續時長
同樣可以通過 show master status; 命令來查看主服務器的運行狀態:

正常運行的主從同步狀態:
Slave_IO_Running: YES
Slave_SQL_Running: YES
Seconds_Behind_Master: 0
問題排查
在理解了主從同步的機制后,再來看今天遇到的問題,通過查看備機狀態,我們觀察在三種狀態下的幾個關鍵屬性值:
mysql show slave status\G;
#狀態一: Slave_IO_State: Reconnecting after a failed master event read
Slave_IO_Running: No
Slave_SQL_Running: Yes
Seconds_Behind_Master: NULL
#狀態二: Slave_IO_State: Waiting for master to send event
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Seconds_Behind_Master: 0
#狀態三: Slave_IO_State: Queueing master event to the relay log
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Seconds_Behind_Master: 636
通過 MySQL 主從復制線程狀態轉變,我們可以看到三種狀態的不同含義:
# 狀態一
# 線程正嘗試重新連接主服務器,當連接重新建立后,狀態變為 Waiting for master to send event。Reconnecting after a failed master event read
# 狀態二
# 線程已經連接上主服務器,正等待二進制日志事件到達。如果主服務器正空閑,會持續較長的時間。如果等待持續 slave_read_timeout 秒,則發生超時。此時,線程認為連接被中斷并企圖重新連接。Waiting for master to send event
# 狀態三
# 線程已經讀取一個事件,正將它復制到中繼日志供 SQL 線程來處理。Queueing master event to the relay log在這里,我們可以猜測,由于某些原因,從服務器不斷的和主服務器進行斷開并嘗試重連,重連成功后又再次斷開。
我們再看看主機的運行情況:

發現問題出在 10.144.63.* 和 10.144.68.* 兩臺機器上,我們查看其中一臺的錯誤日志:
190214 11:33:20 [Note] Slave: received end packet from server, apparent master shutdown:
190214 11:33:20 [Note] Slave I/O thread: Failed reading log event, reconnecting to retry, log mysql-bin.005682 at postion 13628070
拿到關鍵字 Slave: received end packet from server, apparent master shutdown: Google 搜索一下,在文章 Confusing MySQL Replication Error Message 中可以看到原因為兩臺備機的 server-id 重復。
One day it happen to me, and took me almost an hour to find that out.
Moving foward I always use a base my.cnf to I copy to any other server and the first thing is to increase the server-id.
Could MySQL just use the servername intead of a numeric value?
問題修復
定位了問題,我們確認下是否重復,發現兩臺備機的該字段確實相同:
vim my.cnf
#replication
log-bin=mysql-bin
# 這個隨機數字相同導致的
server-id=177230069
sync_binlog=1
看完上述內容,你們掌握 MySQL 中怎么實現主從同步機制的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注丸趣 TV 行業資訊頻道,感謝各位的閱讀!
向 AI 問一下細節











