共計 4829 個字符,預計需要花費 13 分鐘才能閱讀完成。
自動寫代碼機器人,免費開通
這篇文章主要介紹了 mysql 中 acid 指的是什么,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓丸趣 TV 小編帶著大家一起了解一下。
一、事務的基本要素(ACID)
1、原子性(Atomicity):事務開始后所有操作,要么全部做完,要么全部不做,不可能停滯在中間環節。事務執行過程中出錯,會回滾到事務開始前的狀態,所有的操作就像沒有發生一樣。也就是說事務是一個不可分割的整體,就像化學中學過的原子,是物質構成的基本單位。
2、一致性(Consistency):事務開始前和結束后,數據庫的完整性約束沒有被破壞。比如 A 向 B 轉賬,不可能 A 扣了錢,B 卻沒收到。其實一致性也是因為原子型的一種表現
3、隔離性(Isolation):同一時間,只允許一個事務請求同一數據,不同的事務之間彼此沒有任何干擾。比如 A 正在從一張銀行卡中取錢,在 A 取錢的過程結束前,B 不能向這張卡轉賬。串行化
4、持久性(Durability):事務完成后,事務對數據庫的所有更新將被保存到數據庫,不能回滾。
二、事務的并發問題
1、臟讀:事務 A 讀取了事務 B 更新的數據,然后 B 回滾操作,那么 A 讀取到的數據是臟數據,與表中最終的實際數據不一致
2、不可重復讀:事務 A 多次讀取同一數據,事務 B 在事務 A 多次讀取的過程中,對數據作了更新并提交,導致事務 A 多次讀取同一數據時,結果 不一致。讀取結果與上次結果不一致
3、幻讀:系統管理員 A 將數據庫中所有學生的成績從具體分數改為 ABCDE 等級,但是系統管理員 B 就在這個時候插入了一條具體分數的記錄,當系統管理員 A 改結束后發現還有一條記錄沒有改過來,就好像發生了幻覺一樣,這就叫幻讀。修改過來了但又被改了,導致結果和預期不一樣
小結:不可重復讀的和幻讀很容易混淆,不可重復讀側重于修改,幻讀側重于新增或刪除。解決不可重復讀的問題只需鎖住滿足條件的行,解決幻讀需要鎖表
三、MySQL 事務隔離級別
事務隔離級別臟讀不可重復讀幻讀讀未提交(read-uncommitted)是是是讀已提交(read-committed)否是是可重復讀(repeatable-read)否否是串行化(serializable)否否否
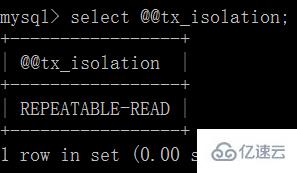
mysql 默認的事務隔離級別為 repeatable-read
四、用例子說明各個隔離級別的情況
1、讀未提交:
(1)打開一個客戶端 A,并設置當前事務模式為 read uncommitted(未提交讀),查詢表 account 的初始值:
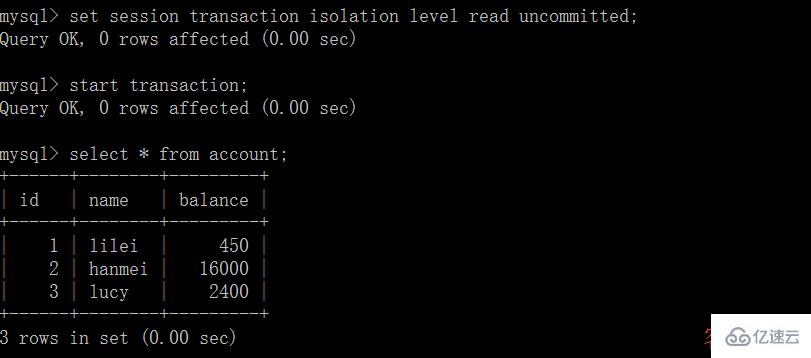
(2)在客戶端 A 的事務提交之前,打開另一個客戶端 B,更新表 account:
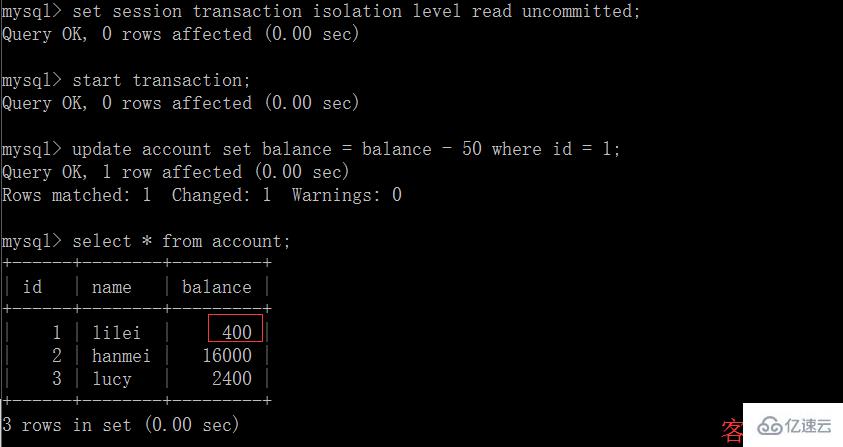
(3)這時,雖然客戶端 B 的事務還沒提交,但是客戶端 A 就可以查詢到 B 已經更新的數據:
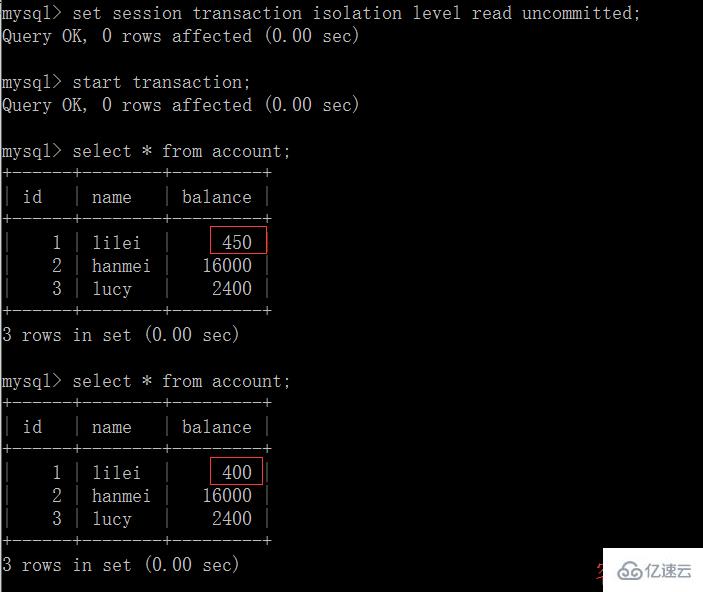
(4)一旦客戶端 B 的事務因為某種原因回滾,所有的操作都將會被撤銷,那客戶端 A 查詢到的數據其實就是臟數據:
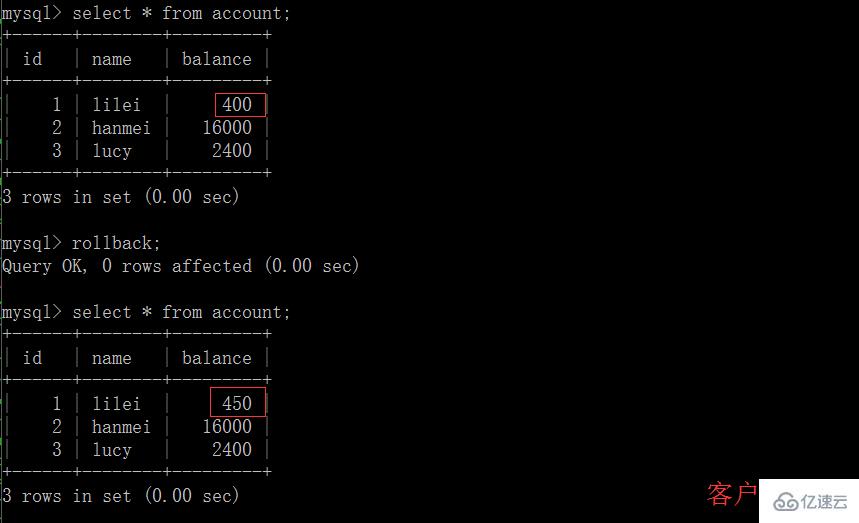
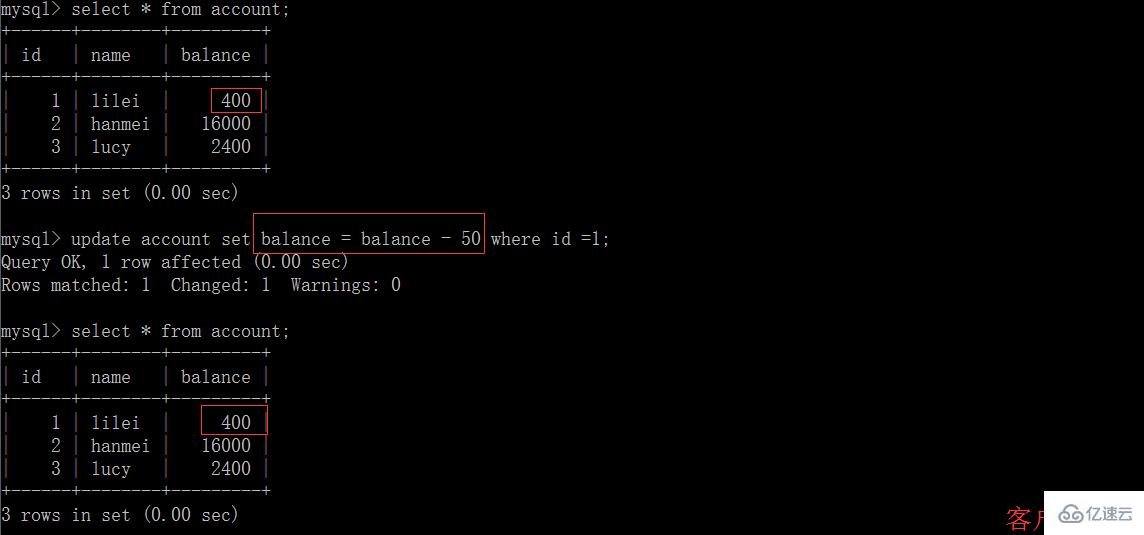
(5)在客戶端 A 執行更新語句 update account set balance = balance – 50 where id =1,lilei 的 balance 沒有變成 350,居然是 400,是不是很奇怪,數據不一致啊,如果你這么想就太天真 了,在應用程序中,我們會用 400-50=350,并不知道其他會話回滾了,要想解決這個問題可以采用讀已提交的隔離級別
2、讀已提交
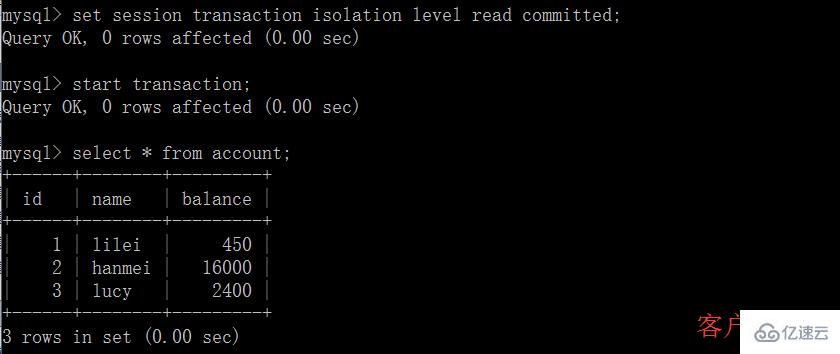
(1)打開一個客戶端 A,并設置當前事務模式為 read committed(未提交讀),查詢表 account 的初始值:
(2)在客戶端 A 的事務提交之前,打開另一個客戶端 B,更新表 account:
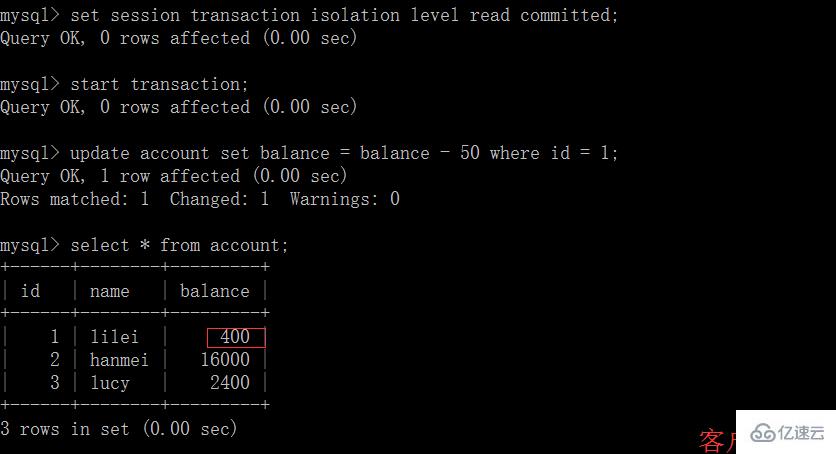
(3)這時,客戶端 B 的事務還沒提交,客戶端 A 不能查詢到 B 已經更新的數據,解決了臟讀問題:
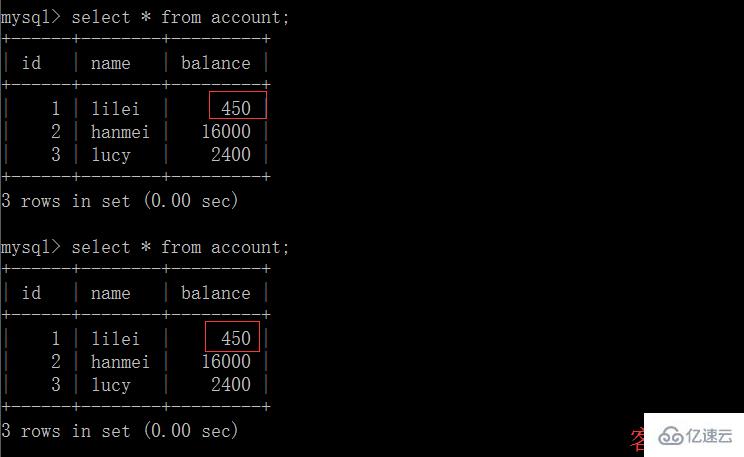
(4)客戶端 B 的事務提交
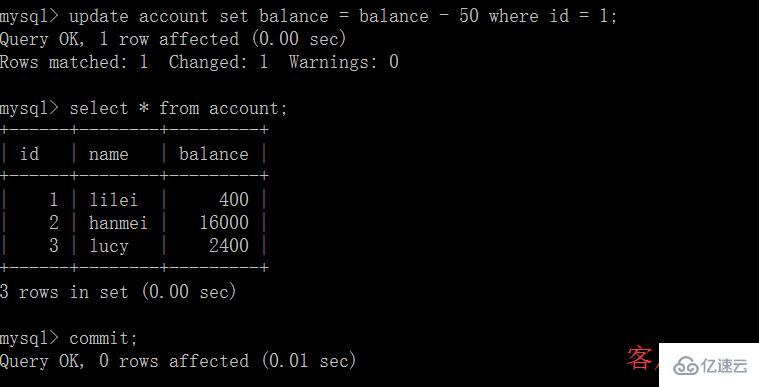
(5)客戶端 A 執行與上一步相同的查詢,結果 與上一步不一致,即產生了不可重復讀的問題

3、可重復讀
(1)打開一個客戶端 A,并設置當前事務模式為 repeatable read,查詢表 account
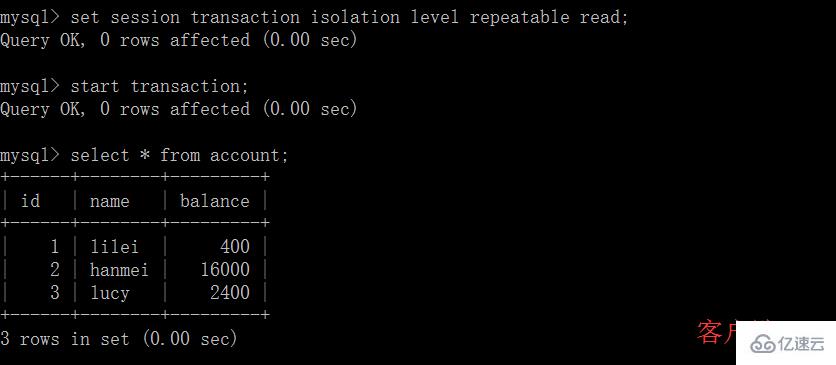
(2)在客戶端 A 的事務提交之前,打開另一個客戶端 B,更新表 account 并提交
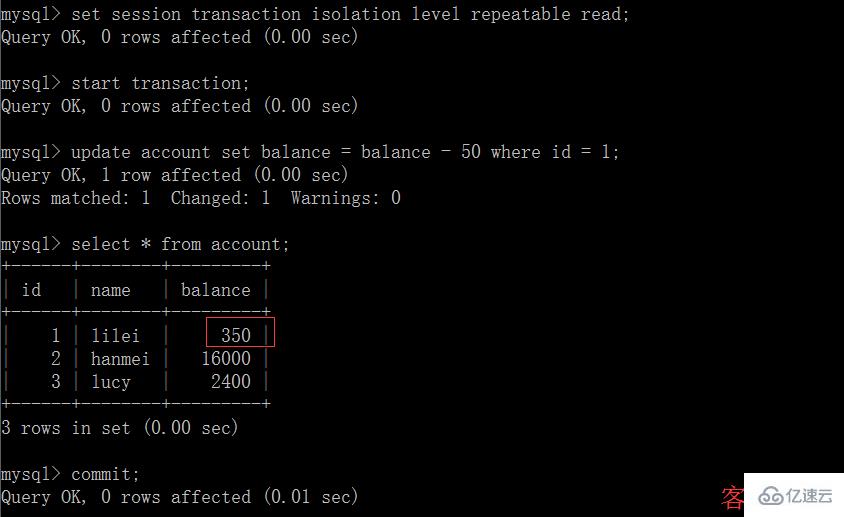
(3)在客戶端 A 執行步驟(1)的查詢:

(4)執行步驟(1),lilei 的 balance 仍然是 400 與步驟(1)查詢結果一致,沒有出現不可重復讀的 問題;接著執行 update balance = balance – 50 where id = 1,balance 沒有變成 400-50=350,lilei 的 balance 值用的是步驟(2)中的 350 來算的,所以是 300,數據的一致性倒是沒有被破壞,這個有點神奇,也許是 mysql 的特色吧,做 dml 時可重復讀數據還是按表中真實數據來
mysql select * from account;
+------+--------+---------+
| id | name | balance |
+------+--------+---------+
| 1 | lilei | 400 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+------+--------+---------+
3 rows in set (0.00 sec)
mysql update account set balance = balance - 50 where id = 1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql select * from account;
+------+--------+---------+
| id | name | balance |
+------+--------+---------+
| 1 | lilei | 300 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+------+--------+---------+
3 rows in set (0.00 sec)
(5) 在客戶端 A 提交事務,查詢表 account 的初始值
mysql commit;
Query OK, 0 rows affected (0.00 sec)
mysql select * from account;
+------+--------+---------+
| id | name | balance |
+------+--------+---------+
| 1 | lilei | 300 |
| 2 | hanmei | 16000 |
| 3 | lucy | 2400 |
+------+--------+---------+
3 rows in set (0.00 sec)(6)在客戶端 B 開啟事務,新增一條數據,其中 balance 字段值為 600,并提交
mysql start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql insert into account values(4, lily ,600);
Query OK, 1 row affected (0.00 sec)
mysql commit;
Query OK, 0 rows affected (0.01 sec)(7) 在客戶端 A 計算 balance 之和,值為 300+16000+2400=18700,沒有把客戶端 B 的值算進去,客戶端 A 提交后再計算 balance 之和,居然變成了 19300,這是因為把客戶端 B 的 600 算進去了
,站在客戶的角度,客戶是看不到客戶端 B 的,它會覺得是天下掉餡餅了,多了 600 塊,這就是幻讀,站在開發者的角度,數據的 一致性并沒有破壞。但是在應用程序中,我們得代碼可能會把 18700 提交給用戶了,如果你一定要避免這情況小概率狀況的發生,那么就要采取下面要介紹的事務隔離級別“串行化”
mysql select sum(balance) from account;
+--------------+
| sum(balance) |
+--------------+
| 18700 |
+--------------+
1 row in set (0.00 sec)
mysql commit;
Query OK, 0 rows affected (0.00 sec)
mysql select sum(balance) from account;
+--------------+
| sum(balance) |
+--------------+
| 19300 |
+--------------+
1 row in set (0.00 sec)4. 串行化
(1)打開一個客戶端 A,并設置當前事務模式為 serializable,查詢表 account 的初始值:
mysql set session transaction isolation level serializable;
Query OK, 0 rows affected (0.00 sec)
mysql start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql select * from account;
+------+--------+---------+
| id | name | balance |
+------+--------+---------+
| 1 | lilei | 10000 |
| 2 | hanmei | 10000 |
| 3 | lucy | 10000 |
| 4 | lily | 10000 |
+------+--------+---------+
4 rows in set (0.00 sec)(2)打開一個客戶端 B,并設置當前事務模式為 serializable,插入一條記錄報錯,表被鎖了插入失敗,mysql 中事務隔離級別為 serializable 時會鎖表,因此不會出現幻讀的情況,這種隔離級別并發性極低,開發中很少會用到。
mysql set session transaction isolation level serializable;
Query OK, 0 rows affected (0.00 sec)
mysql start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql insert into account values(5, tom ,0);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction補充:
1、SQL 規范所規定的標準,不同的數據庫具體的實現可能會有些差異
2、mysql 中默認事務隔離級別是可重復讀時并不會鎖住讀取到的行
3、事務隔離級別為讀提交時,寫數據只會鎖住相應的行
4、事務隔離級別為可重復讀時,如果有索引(包括主鍵索引)的時候,以索引列為條件更新數據,會存在間隙鎖間隙鎖、行鎖、下一鍵鎖的問題,從而鎖住一些行;如果沒有索引,更新數據時會鎖住整張表。
5、事務隔離級別為串行化時,讀寫數據都會鎖住整張表
6、隔離級別越高,越能保證數據的完整性和一致性,但是對并發性能的影響也越大,魚和熊掌不可兼得啊。對于多數應用程序,可以優先考慮把數據庫系統的隔離級別設為 Read Committed,它能夠避免臟讀取,而且具有較好的并發性能。盡管它會導致不可重復讀、幻讀這些并發問題,在可能出現這類問題的個別場合,可以由應用程序采用悲觀鎖或樂觀鎖來控制。
感謝你能夠認真閱讀完這篇文章,希望丸趣 TV 小編分享的“mysql 中 acid 指的是什么”這篇文章對大家有幫助,同時也希望大家多多支持丸趣 TV,關注丸趣 TV 行業資訊頻道,更多相關知識等著你來學習!
向 AI 問一下細節











