共計 4953 個字符,預計需要花費 13 分鐘才能閱讀完成。
自動寫代碼機器人,免費開通
這篇文章主要介紹了 Redis 中數據結構是什么,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓丸趣 TV 小編帶著大家一起了解一下。
在實際開發,Redis 使用會頻繁,那么在使用過程中我們該如何正確抉擇數據類型呢?哪些場景下適用哪些數據類型。而且在面試中也很常會被面試官問到 Redis 數據結構方面的問題:
Redis 為什么快呢?
為什么查詢操作會變慢了?
Redis Hash rehash 過程
為什么使用哈希表作為 Redis 的索引
當我們分析理解了 Redis 數據結構,可以為了我們在使用 Redis 的時候,正確抉擇數據類型使用,提升系統性能。【相關推薦:Redis 視頻教程】
Redis 底層數據結構
Redis 是一個內存鍵值 key-value 數據庫,且鍵值對數據保存在內存中,因此 Redis 基于內存的數據操作,其效率高,速度快;
其中,Key 是 String 類型,Redis 支持的 value 類型包括了 String、List、Hash、Set、Sorted Set、BitMap 等。Redis 能夠之所以能夠廣泛地適用眾多的業務場景,基于其多樣化類型的 value。
而 Redis 的 Value 的數據類型是基于為 Redis 自定義的對象系統 redisObject 實現的,
typedef struct redisObject{
// 類型
unsigned type:4;
// 編碼
unsigned encoding:4;
// 指向底層實現數據結構的指針
void *ptr;
…..
}redisObject 除了記錄實際數據,還需要額外的內存空間記錄數據長度、空間使用等元數據信息,其中包含了 8 字節的元數據和一個 8 字節指針,指針指向具體數據類型的實際數據所在位置:
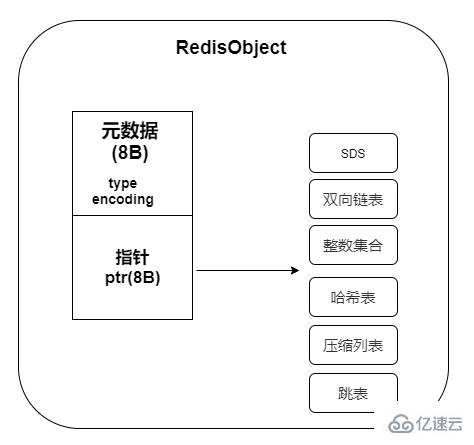
其中,指針指向的就是基于 Redis 的底層數據結構存儲數據的位置,Redis 的底層數據結構:SDS,雙向鏈表、跳表,哈希表,壓縮列表、整數集合實現的。
那么 Redis 底層數據結構是怎么實現的呢?
Redis 底層數據結構實現
我們先來看看 Redis 比較簡單的 SDS, 雙向鏈表,整數集合。
SDS、雙向鏈表和整數集合
SDS,使用 len 字段記錄已使用的字節數,將獲取字符串長度復雜度降低為 O(1),而且 SDS 是惰性釋放空間的,你 free 了空間,系統把數據記錄下來下次想用時候可直接使用。不用新申請空間。
整數集合,在內存中分配一塊地址連續的空間,數據元素會挨著存放,不需要額外指針帶來空間開銷,其特點為內存緊湊節省內存空間,查詢復雜度為 O(1)效率高,其他操作復雜度為 O(N);
雙向鏈表,在內存上可以為非連續、非順序空間,通過額外的指針開銷前驅 / 后驅指針串聯元素之間的順序。
其特點為節插入 / 更新數據復雜度為 O(1)效率高,查詢復雜度為 O(N);
Hash 哈希表
哈希表,其實類似是一個數組,數組的每個元素稱為一個哈希桶,每個哈希桶中保存了鍵值對數據,且哈希桶中的元素使用 dictEntry 結構,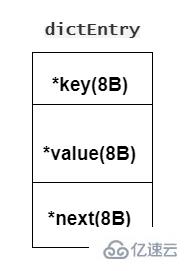
因此,哈希桶元素保存的并不是鍵值對值本身,而是指向具體值的指針,所以在保存每個鍵值對的時候會額外空間開銷,至少有增加 24 個字節,特別是 Value 為 String 的鍵值對,每一個鍵值對就需要額外開銷 24 個字節空間。當保存數據小,額外開銷比數據還大時,這時為了節省空間,考慮換數據結構。
那來看看全局哈希表全圖:
雖然哈希表操作很快,但 Redis 數據變大后,就會出現一個潛在的風險:哈希表的沖突問題和 rehash 開銷問題,這可以解釋為什么哈希表操作變慢了?
當往哈希表中寫入更多數據時,哈希沖突是不可避免的問題,Redis 解決哈希沖突的方式,就是鏈式哈希,同一個哈希桶中的多個元素用一個鏈表來保存,它們之間依次用指針連接,如圖所示: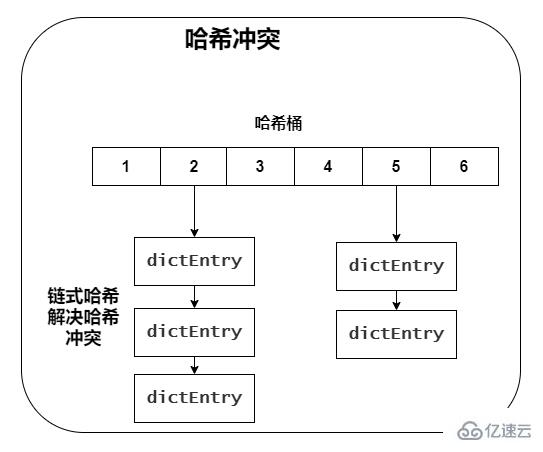
當哈希沖突也會越來越多,這就會導致某些哈希沖突鏈過長,進而導致這個鏈上的元素查找耗時長,效率降低。
為了解決哈希沖突帶了的鏈過長的問題,進行 rehash 操作,增加現有的哈希桶數量,分散單桶元素數量。那么 rehash 過程怎么樣執行的呢?
Rehash
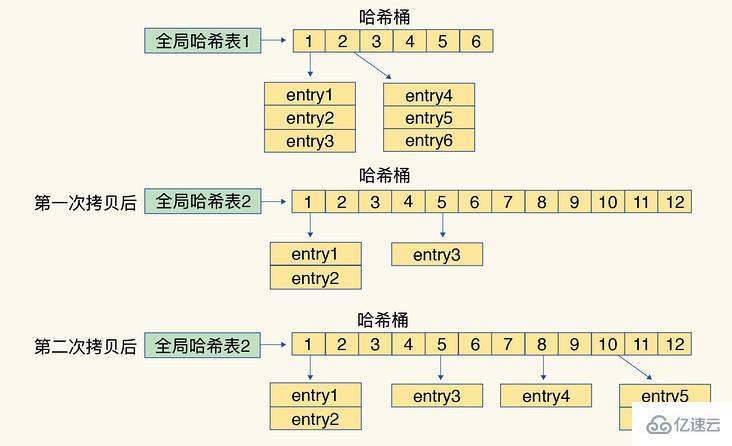
為了使 rehash 操作更高效,使用兩個全局哈希表:哈希表 1 和哈希表 2,具體如下:
將哈希表 2 分配更大的空間,
把哈希表 1 中的數據重新映射并拷貝到哈希表 2 中;
釋放哈希表 1 的空間
但由于表 1 和表 2 在重新映射復制時數據大,如果一次性把哈希表 1 中的數據都遷移完,會造成 Redis 線程阻塞,無法服務其他請求。
為了避免這個問題,保證 Redis 能正常處理客戶端請求,Redis 采用了漸進式 rehash。
每處理一個請求時,從哈希表 1 中依次將索引位置上的所有 entries 拷貝到哈希表 2 中,把一次性大量拷貝的開銷,分攤到了多次處理請求的過程中,避免了耗時操作,保證了數據的快速訪問。
在理解完 Hash 哈希表相關知識點后,看看不常見的壓縮列表和跳表。
壓縮列表與跳表
壓縮列表,在數組基礎上,在壓縮列表在表頭有三個字段 zlbytes、zltail 和 zllen,分別表示列表長度、列表尾的偏移量和列表中的 entry 個數;壓縮列表在表尾還有一個 zlend,表示列表結束。
優點:內存緊湊節省內存空間,內存中分配一塊地址連續的空間,數據元素會挨著存放,不需要額外指針帶來空間開銷;查找定位第一個元素和最后一個元素,可以通過表頭三個字段的長度直接定位,復雜度是 O(1)。
跳表,在鏈表的基礎上,增加了多級索引,通過索引位置的幾個跳轉,實現數據的快速定位,如下圖所示:
比如查詢 33
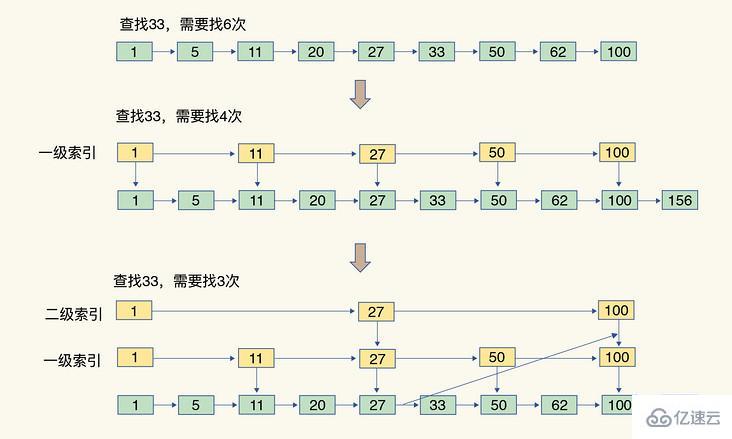
特點:當數據量很大時,跳表的查找復雜度為 O(logN)。
綜上所述,可以得知底層數據結構的時間復雜度:
數據結構類型時間復雜度哈希表 O(1)整數數組 O(N)雙向鏈表 O(N)壓縮列表 O(N)跳表 O(logN)
Redis 自定義的對象系統類型即為 Redis 的 Value 的數據類型,Redis 的數據類型是基于底層數據結構實現的,那數據類型有哪些呢?
Redis 數據類型
String、List、Hash、Sorted Set、Set 比較常見的類型,其與底層數據結構對應關系如下:
數據類型數據結構 StringSDS(簡單動態字符串)List 雙向鏈表
壓縮列表 Hash 壓縮列表 br/ 哈希表 Sorted Set 壓縮列表 br/ 跳表 Set 哈希表 br/ 整數數組
數據類型對應特點跟其實現的底層數據結構差不多,性質也是一樣的, 且
String,基于 SDS 實現,適用于簡單 key-value 存儲、setnx key value 實現分布式鎖、計數器(原子性)、分布式全局唯一 ID。
List,按照元素進入 List 的順序進行排序的,遵循 FIFO(先進先出)規則,一般使用在 排序統計以及簡單的消息隊列。
Hash,是字符串 key 和字符串 value 之間的映射,十分適合用來表示一個對象信息,特點添加和刪除操作復雜度都是 O(1)。
Set,是 String 類型元素的無序集合,集合成員是唯一的,這就意味著集合中不能出現重復的數據。基于哈希表實現的,所以添加,刪除,查找的復雜度都是 O(1)。
Sorted Set, 是 Set 的類型的升級,不同的是每個元素都會關聯一個 double 類型的分數,通過分數排序,可以范圍查詢。
那我們再來看看這些數據類型,Redis Geo、HyperLogLog、BitMap?
Redis Geo,將地球看作為近似為球體,基于 GeoHash 將二維的經緯度轉換成字符串,來實現位置的劃分跟指定距離的查詢。特點一般使用在跟位置有關的應用。
HyperLogLog,是一種概率數據結構,它使用概率算法來統計集合的近似基數,錯誤率大概在 0.81%。當集合元素數量非常多時,它計算基數所需的空間總是固定的,而且還很小,適合使用做 UV 統計。
BitMap,用一個比特位來映射某個元素的狀態,只有 0 和 1 兩種狀態,非常典型的二值狀態,且其本身是用 String 類型作為底層數據結構實現的一種統計二值狀態的數據類型 ,優勢大量節省內存空間,可是使用在二值統計場景。
在理解上述知識后,我們接下來討論一下根據哪些策略選擇相對應的應用場景下的 Redis 數據類型?
選擇合適的 Redis 數據類型策略
在實際開發應用中,Redis 可以適用于眾多的業務場景,但我們需要怎么選擇數據類型存儲呢?
主要依據就是時間 / 空間復雜度,在實際的開發中可以考慮以下幾個點:
數據量,數據本身大小
集合類型統計模式
支持單點查詢 / 范圍查詢
特殊使用場景
數據量,數據本身大小
當數據量比較大,數據本身比較小,使用 String 就會使用額外的空間大大增加,因為使用哈希表保存鍵值對,使用 dictEntry 結構保存,會導致保存每個鍵值對時額外保存 dictEntry 的三個指針的開銷,這樣就會導致數據本身小于額外空間開銷,最終會導致存儲空間數據大小遠大于原本數據存儲大小。
可以使用基于整數數組和壓縮列表實現了 List、Hash 和 Sorted Set,因為整數數組和壓縮列表在內存中都是分配一塊地址連續的空間,然后把集合中的元素一個接一個地放在這塊空間內,非常緊湊,不用再通過額外的指針把元素串接起來,這就避免了額外指針帶來的空間開銷。而且采用集合類型時,一個 key 就對應一個集合的數據,能保存的數據多了很多,但也只用了一個 dictEntry,這樣就節省了內存。
集合類型統計模式
Redis 集合類型統計模式常見的有:
聚合統計(交集、差集、并集統計): 對多個集合進行聚合計算時,可以選擇 Set;
排序統計(要求集合類型能對元素保序):Redis 中 List 和 Sorted Set 是有序集合,List 是按照元素進入 List 的順序進行排序的,Sorted Set 可以根據元素的權重來排序;
二值狀態統計(集合元素的取值就只有 0 和 1 兩種):Bitmap 本身是用 String 類型作為底層數據結構實現的一種統計二值狀態的數據類型,Bitmap 通過 BITOP 按位 與、或、異或的操作后使用 BITCOUNT 統計 1 的個數。
基數統計(統計一個集合中不重復的元素的個數):HyperLogLog 是一種用于統計基數的數據集合類型,統計結果是有一定誤差的,標準誤算率是 0.81%。需要精確統計結果的話,用 Set 或 Hash 類型。

Set 類型,適用統計用戶 / 好友 / 關注 / 粉絲 / 感興趣的人集合聚合操作,比如
統計手機 APP 每天的新增用戶數
兩個用戶的共同好友
Redis 中 List 和 Sorted Set 是有序集合,使用應對集合元素排序需求,比如
最新評論列表
排行榜
Bitmap 二值狀態統計,適用數據量大,且可以使用二值狀態表示的統計,比如:
簽到打卡,當天用戶簽到數
用戶周活躍
用戶在線狀態
HyperLogLog 是一種用于統計基數的數據集合類型,統計一個集合中不重復的元素個數,比如
統計網頁的 UV,一個用戶一天內的多次訪問只能算作一次
支持單點查詢 / 范圍查詢
Redis 中 List 和 Sorted Set 是有序集合支持范圍查詢,但是 Hash 是不支持范圍查詢的
特殊使用場景
消息隊列,使用 Redis 作為消息隊列的實現,要消息的基本要求消息保序、處理重復的消息和保證消息可靠性,方案有如下:
基于 List 的消息隊列解決方案
基于 Streams 的消息隊列解決方案
基于 List 基于 Strems 消息保序使用 LPUSH/RPOP 使用 XADD/XREAD 阻塞讀取使用 BRPOP 使用 XREAD block 重復消息處理生產者自行實現全局唯一 IDStreams 自動生成全局唯一 ID 消息可靠性使用 BRPOPLPUSH 使用 PENDING List 自動留存消息適用場景消息總量小消息總量大,需要消費組形式讀取數據
基于位置 LBS 服務,使用 Redis 的特定 GEO 數據類型實現,GEO 可以記錄經緯度形式的地理位置信息,被廣泛地應用在 LBS 服務中。 比如: 打車軟件是怎么基于位置提供服務的。
Redis 之所以那么快,是因為其基于內存的數據操作和使用 Hash 哈希表作為索引,其效率高,速度快,而且得益于其底層數據多樣化使得其可以適用于眾多場景,不同場景中選擇合適的數據類型可以提升其查詢性能。
感謝你能夠認真閱讀完這篇文章,希望丸趣 TV 小編分享的“Redis 中數據結構是什么”這篇文章對大家有幫助,同時也希望大家多多支持丸趣 TV,關注丸趣 TV 行業資訊頻道,更多相關知識等著你來學習!
向 AI 問一下細節










