共計 4095 個字符,預計需要花費 11 分鐘才能閱讀完成。
自動寫代碼機器人,免費開通
這篇文章主要介紹了 SQL 中 Join 的使用示例,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓丸趣 TV 小編帶著大家一起了解一下。
一. 基本概念
關于 sql 語句中的連接(join)關鍵字,是較為常用而又不太容易理解的關鍵字,下面這個例子給出了一個簡單的解釋 –建表 user1,user2:
table1 : create table user2(id int, user_name varchar(10), over varchar(10));
insert into user1 values(1,‘tangseng ,‘dtgdf
insert into user1 values(2,‘sunwukong ,‘dzsf
insert into user1 values(1,‘zhubajie ,‘jtsz
insert into user1 values(1,‘shaseng ,‘jslh
table2 : create table user2(id int, user_name varchar(10), over varchar(10));
insert into user2 values(1,‘sunwukong ,‘chengfo
insert into user2 values(2,‘niumowang ,‘chengyao
insert into user2 values(3,‘jiaomowang ,‘chengyao
insert into user2 values(4,‘pengmowang ,‘chengyao
SQL 標準中 Join 的類型
1. 內連接(inner join 或 join)
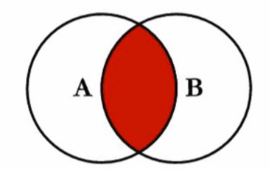
(1). 概念:內聯接是基于連接謂詞將兩張表的列結合在一起,產生新的結果表
(2). 內連接維恩圖:
(3).sql 語句
select a.id, a.user_name, b.over from user1 a inner join user2 b on a.user_name=b.user_name;
結果:

2. 外連接
外連接包括左向外聯接、右向外聯接或完整外部聯接
a. 左外連接:left join 或 left outer join
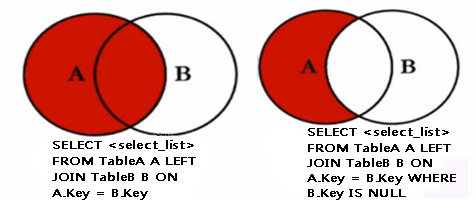
(1)概念:左向外聯接的結果集包括 LEFT OUTER 子句中指定的左表的所有行,而不僅僅是聯接列所匹配的行。如果左表的某行在右表中沒有匹配行,則在相關聯的結果集行中右表的所有選擇列表列均為空值(null)。
(2)左外連接維恩圖:
(3)sql 語句:
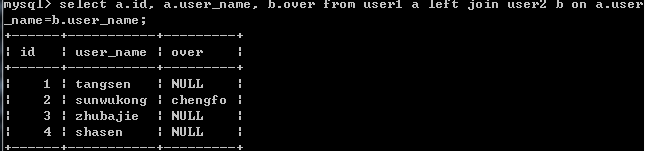
select a.id, a.user_name, b.over from user1 a left join user2 b on a.user_name=b.user_name;
結果:
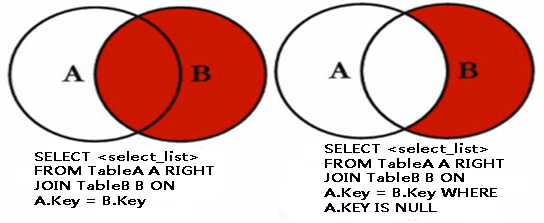
b. 右外連接:right join 或 right outer join
(1)右向外聯接是左向外聯接的反向聯接。將返回右表的所有行。如果右表的某行在左表中沒有匹配行,則將為左表返回空值。
(2)右外連接維恩圖:
(3)sql 語句
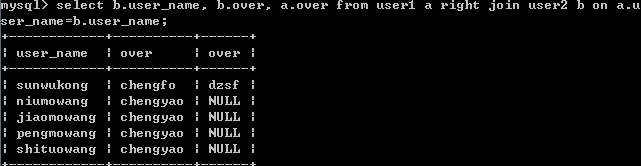
select b.user_name, b.over, a.over from user1 a right join user2 b on a.user_name=b.user_name;
結果:
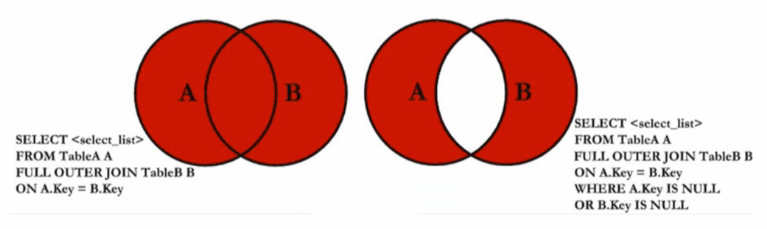
c. 全外連接:full join 或 full outer join
(1)完整外部聯接返回左表和右表中的所有行。當某行在另一個表中沒有匹配行時,則另一個表的選擇列表列包含空值。如果表之間有匹配行,則整個結果集行包含基表的數據值。
(2)右外連接維恩圖:
(3)sql 語句
select a.id, a.user_name, b.over from user1 a full join user2 b on a.user_name=b.user_name
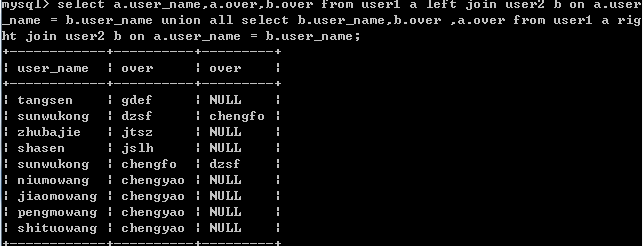
在 mysql 中查詢全連接會報 1064 的錯誤,mysql 不支持全連接查詢,代替語句:
select a.user_name,a.over,b.over from user1 a left join user2 b on a.user_name = b.user_name union all select b.user_name,b.over ,a.over from user1 a right join user2 b on a.user_name = b.user_name;
結果:
3. 笛卡爾連接(交叉連接)
1. 概念:沒有 WHERE 子句的交叉聯接將產生聯接所涉及的表的笛卡爾積。第一個表的行數乘以第二個表的行數等于笛卡爾積結果集的大小。(user1 和 user2 交叉連接產生 4 *4=16 條記錄)
2. 交叉連接:cross join (不帶條件 on)
3.sql 語句:
select a.user_name,b.user_name, a.over, b.over from user1 a cross join user2 b;
二. 使用技巧
1. 使用 join 更新表
我們使用下面語句將 user1 表中同時存在 user1 表和 user2 表中記錄的 over 字段更新為‘qtda。
update user1 set over= qtds where user1.user_name in (select b.user_name from user1 a inner join user2 b on a.user_name = b.user_name);
這條語句在 sql server, oracle 中都可以正確執行,在 mysql 卻報錯,mysql 不支持更新子查詢的表,那么我們使用下面語句可以在做到。
update user1 a join (select b.user_name from user1 a join user2 b on a.user_name = b.user_name) b on a.user_name = b.user_name set a.over =‘qtds
2. 使用 join 優化子查詢
子查詢效率比較低效,使用下面語句進行查詢
select a.user_name, a.over,(select over from user2 b where a.user_name=b.user_name) as over2 from user1 a;
使用 join 優化子查詢,可以實現同樣的效果
select a.user_name, a.over, b.over as over2 from user1 a left join user2
b on a.user_name = b.user_name;
3. 使用 join 優化聚合子查詢
引入一張新表:user_kills
create table user_kills(user_id int, timestr varchar(20), kills int(10));
insert into user_kills values(2,‘2015-5-12 , 20);
insert into user_kills values(2,‘2015-5-15 , 18);
insert into user_kills values(3,‘2015-5-11 , 16);
insert into user_kills values(3,‘2015-5-14 , 13);
insert into user_kills values(3,‘2015-5-16 , 17);
insert into user_kills values(4,‘2015-5-12 , 16);
insert into user_kills values(4,‘2015-5-10 , 13);
查詢 user1 中每人對應 user_kills 表中 kills 最大的日期,使用聚合子查詢語句:
select a.user_name,b.timestr, b.kills from user1 a join user_kills b on a
.id = b.user_id where b.kills = (select MAX(c.kills) from user_kills c where c.user_id = b.user_id);
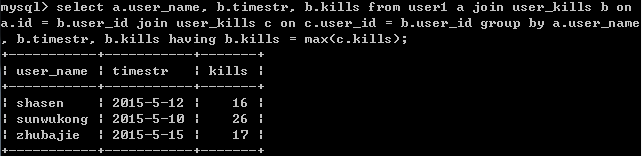
使用 join 優化聚合子查詢(避免子查詢)
select a.user_name, b.timestr, b.kills from user1 a join user_kills b on
a.id = b.user_id join user_kills c on c.user_id = b.user_id group by a.user_name, b.timestr, b.kills having b.kills = max(c.kills);
結果:
4. 實現分組選擇數據
要求查詢出 user1 中每個人 kills 對多的前兩天。
首先,我們可以通過下面語句查詢出某個人 kills 最多的兩天;
select a.user_name, b.timestr, b.kills from user1 a join user_kills b on
a.id = b.user_id where a.user_name = sunwukong order by b.kills desc limit 2;
那么如何通過一個語句查詢出所有人 kills 最多的兩天的呢?看下面的語句:
WITH tmp AS (select a.user_name, b.timestr, b.kills, ROW_NUMBER() over(partition by a.user_name order by b.kills) cnt from user1 a join user_kills b on a.id = b.user_id) select * from tmp where cnt
上面的語句在 sql server 和 oracle 都是支持的,但是 mysql 不支持分組排序函數 ROW_NUMBER(), 下面提供一種替代方法:
select d.user_name,c.timestr, kills from (select user_id, timestr, kills, (select count(*) from user_kills b where b.user_id = a.user_id and a.kills = b.kills) as cnt from user_kills a group by user_id, timestr, kills) c join user1 d on c.user_id = d.id where cnt
結果:

感謝你能夠認真閱讀完這篇文章,希望丸趣 TV 小編分享的“SQL 中 Join 的使用示例”這篇文章對大家有幫助,同時也希望大家多多支持丸趣 TV,關注丸趣 TV 行業資訊頻道,更多相關知識等著你來學習!
向 AI 問一下細節










