共計 9021 個字符,預計需要花費 23 分鐘才能閱讀完成。
自動寫代碼機器人,免費開通
這篇文章給大家分享的是有關詳細分析 MySQL 數據庫的基礎用法的內容。丸趣 TV 小編覺得挺實用的,因此分享給大家做個參考,一起跟隨丸趣 TV 小編過來看看吧。
目錄
庫相關內容
表的詳細操作
數據類型
枚舉與集合
存儲引擎(了解即可)
庫相關內容
MySQL 一些默認庫
information_schema:虛擬庫,不占用磁盤空間,存儲的是數據庫啟動后的一些參數,如用戶表信息、列信息、權限信息、字符信息等
performance_schema:MySQL 5.5 開始新增一個數據庫:主要用于收集數據庫服務器性能參數,記錄處理查詢請求時發生的各種事件、鎖等現象
mysql:授權庫,主要存儲系統用戶的權限信息
test:MySQL 數據庫系統自動創建的測試數據庫
ps:部分 MySQL 可能沒有 test 庫,如筆者的 8.0,用于 sys 代替了 test 庫
創建數據庫就不用說了(在上一篇有提到),了解一下創建數據庫時的命名規則:
可以由字母、數字、下劃線、@、#、$
區分大小寫
唯一性
不能使用關鍵字如 create select
不能單獨使用數字
最長 128 位
通常命名都是字母、數字、下劃線、例如上面的 @#$ 建議不要使用,后續我們如果通過代碼連接庫,里面的符號有可能會與代碼的語法沖突。
表的詳細操作
創建表的約束條件(詳細留到下一章講解)
create table student(
id int not null,
name varchar(10) not null # 最后一個字段不能使用逗號);上面操作表示,約束了 student 這個表的 id 和 name 字段插入值時,不能為空
insert student values(null, jack產生報錯:ERROR 1048 (23000): Column‘id’cannot be null
告訴我們 id 不能為空
更改表的補充操作
約束條件是可有可無的,根據自身對表的需求。
修改表名
alter table 表名 rename 新表名;增加字段
alter table 表名 add 字段名 數據類型 約束條件(根據需求添加);# 添加多個字段 alter table 表名 add 字段名 1 數據類型,add 字段名 2 數據類型;# 在開頭增加字段 alter table 表名 add 字段 數據類型 first;# 在某個字段后面增加字段 alter table 表名 add 字段 數據類型 after 字段;刪除字段
alter table 表名 drop 字段修改字段
# 修改字段的類型或者約束條件 alter table 表名 modify 新的數據類型 新的約束條件;# 修改整個字段 alter table 表名 change 舊字段名 新字段名 新字段數據類型;# 修改字段名 alter table 表名 rename column 原字段名 to 新字段名;復制表
當我們通過 select 查詢表的時候,呈現給我們的是一張:虛擬表,即存在內存中的內容,不能夠保存下來,我們通過復制,可以拿到我們想要的表數據
創建一張表演示
insert student values(1, jack),(2, tom),(3, jams),(4, rous
我們需要將 id 大于 2 記錄的內容保存到一張新的表
create table new_studnet select * from student where id 2;
或者我們只是想復制表的數據結構,除了記錄(數據)以外,其它所有信息
create table new_student2 select * from student where 0 1;這種判斷永遠為假,表示無法復制表的記錄,但是可以復制它的數據結構
數據類型
1、整數類型:TINYINT SMALLINT MEDIUMINT INT BIGINT
作用:存儲年齡,等級,id,各種號碼等
不同的整數類型,存儲的數值范圍不同。
比如:當我們選擇 int 類型創建一個字段后,這張表就會多占用 4 個字節。我們需要根據自己存入值的范圍來選擇整數類型,可以節省空間。
2、浮點類型:float、double、decimal(可以寫成 dec)
作用:存儲薪資、身高、體重、體質參數等
float(255,30):整數可以支持到 255 個數字個數,并且支持 30 位以內的小數
double(255,30):整數可以支持到 255 范圍內,并且支持 30 位以內的小數
dec(65,30):整數可以支持到 60 范圍內,并且支持 30 位以內的小數
單精度浮點數(非準確小數值),m 是數字總個數,d 是小數點后個數。m 最大值為 255,d 最大值為 30
那么這三個浮點類型的區別在于哪里?答案是:精準度
實例:創建 3 張不同浮點類型的表
create table f1(id float(255,30));create table f2(id double(255,30));create table f3(id dec(66,30));插入值
insert f1 values(1.1111111111111111111111111111111); # 小數點后 31 個 1insert f2 values(1.1111111111111111111111111111111);insert f3 values(1.1111111111111111111111111111111);效果
decaimal 能夠存儲精確值的原因在于其內部按照字符串存儲。
通常我們使用 float 就足夠了,要求再高一點使用 double 就可以了,如果對精準度要求特別高那么就使用 decaimal,但是 decaimal 整數長度不如 float 與 double
3、日期類型:DATE TIME DATETIME TIMESTAMP YEAR
作用:存儲用戶注冊時間,文章發布時間,員工入職時間,出生時間,過期時間等
在我們創建表字段時,可以指定某個字段傳入的日期是什么,以下可選:
date # 1000-01-01/9999-12-31time # -838:59:59/838:59:59year # 支持 1901/2155datetime # 日期時間 1000-01-01 00:00:00/9999-12-31 23:59:59timestamp # 日期時間 1970-01-01 00:00:00/2037 某時實例:創建表
create table info(
id int,
name varchar(10),
birth date,
class_time time,
reg_time datetime,
born_year year);
插入記錄
nsert info values(
jack ,
1999-01-01 ,
08:30:00 ,
2020-01-01 10:15:00 ,
1999
MySQL 提供的兩種日期時間都可以提供給我們使用,那它們之間的區別在哪里呢
datetime 與 timestamp 的區別
首先占用空間:datetime 占用 8 字節大小,timestamp 占用 4 字節大小
在 5.x 以上版本,改動表后使用 timestamp 可以自動給我們填上當前系統時間,筆者的 8.0 不能自動填上系統時間,和 datietime 呈現的效果一樣了,只是上限的時間不同。我們如果要達到這個效果,可以創建時補充如下參數
create table d2(
id int,
name varchar(10),
now timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP);
我們添加數據時,可以根據前兩個來字段添加,最后一個讓它自動補充。
# insert d2 values(1, jack 錯誤寫法,因為這個必須要給所有字段設置值 insert d2(id,name) values(1, jack # 正確寫法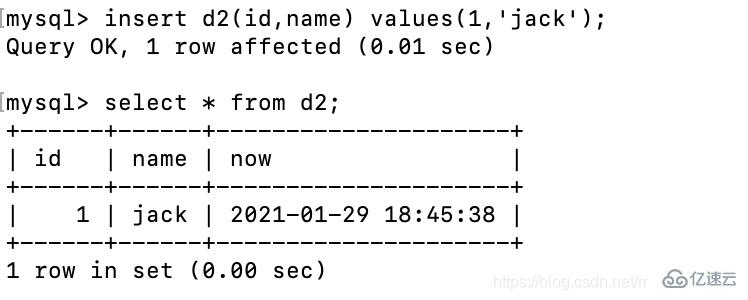
4、字符串類型:char、varchar
char:簡單粗暴,浪費空間,存取速度快
字符長度范圍:0-255(一個中文是一個字符,是 utf8 編碼的 3 個字節)
存儲 char 類型的值時,會往右填充空格來滿足長度
例如:指定長度為 10,存 10 個字符則報錯,存 10 個字符則用空格填充直到湊夠 10 個字符存儲
在檢索或者說查詢時,查出的結果會自動刪除尾部的空格,除非我們打開 pad_char_to_full_length SQL 模式(SET sql_mode =‘PAD_CHAR_TO_FULL_LENGTH’;)
varchar 類型:變長,精準,節省空間,存取速度慢
字符長度范圍:0-65535(如果大于 21845 會提示用其他類型。mysql 行最大限制為 65535 字節。
varchar 類型存儲數據的真實內容,不會用空格填充,如果’ab , 尾部的空格也會被存起來
強調:varchar 類型會在真實數據前加 1 -2Bytes 的前綴,該前綴用來表示真實數據的 bytes 字節數(1-2Bytes 最大表示 65535 個數字,正好符合 mysql 對 row 的最大字節限制,即已經足夠使用)
如果真實的數據 255bytes 則需要 1Bytes 的前綴(1Bytes=8bit 2** 8 最大表示的數字為 255)
如果真實的數據 255bytes 則需要 2Bytes 的前綴(2Bytes=16bit 2**16 最大表示的數字為 65535)
尾部有空格會保存下來,在檢索或者說查詢時,也會正常顯示包含空格在內的內容
char(4)Storage Requiredvarchar(4)Storage Required’ ’4 字節‘’1 字節 ab ’4 字節‘ab’2 字節‘abcd’4 字節‘abcd’5 字節‘abcdef’報錯‘abcde’報錯
區分介紹:
char 類型定長,不管存多少數據,如果未達到指定長度,則空格補充
varchar 類型變長:因為取的時候,不知道 varchar 類型取了多少個數據,所以默認會在開頭放入 1 個字節的頭部。(底層存儲機制,只要我們自身輸入的內容沒有超過定義的長度就不會報錯)
char 一定比 varchar 更浪費空間?
如果存儲內容相同長度的情況下,varchar 占用大小會大于 char
但是我們平常還是常使用 varchar,因為我們存儲內容時,無法確定內容的大小,所以通常使用 varchar,也就多占那么 1 - 2 個字節,而 char 的話,則占用更多的大小。
注意:
如果存儲的內容是網頁或網絡上的某一篇文章,建議不要把文字全部保存到數據庫,直接將鏈接放上去保存即可。
嚴格模式下的 MySQL,如果存儲內容超過了字符串類型定義的長度,那么則會報錯,而非嚴格模式下的 MySQL,則是不保存超出的內容,并發出警告信息。
查看字符的個數
create table c1(x char(10));create table c2(x varchar(10));select char_length(x) as 內容長度 from c1;select char_length(x) as 內容長度 from c2;
很奇怪的就是,char 類型并沒有占用 10 個字節,是因為 MySQL 幫我們隱藏了,只呈現給我們自身存儲的內容,調整一下就可以讓它顯出原形。
set sql_mode = PAD_CHAR_TO_FULL_LENGTH
查詢時候的問題
很明顯,這兩個類型雖然內容一樣,但是 char 占用字符更長
枚舉與集合
通過 enum 函數與 set 函數,在創建表時,定義某個字段在插入值時,值的內容是否匹配。
create table test(
id int,
name varchar(10),
gender enum(男 , 女 , 未知),
hobbies set(game , music , book , movie
enum:在向 gender 這個字段插入值時,只能輸入其中一的值
set:在向 hobbies 這個字段插入值時,可以輸入其中多個值,通過逗號隔開
insert test values(1, jack , 男 , game,book
如果我們輸入的內容,與函數內定義的不符,非嚴格模式發出警告信息,嚴格模式直接報錯

筆者的 MySQL 為嚴格模式(利于開發)
select @@sql_mode; # 查看當前模式存儲引擎(了解即可)
首先確定一點,存儲引擎的概念是 MySQL 里面才有的,不是所有的關系型數據庫都有存儲引擎這個概念。
數據庫中的表也應該有不同的類型,表的類型不同,會對應 mysql 不同的存取機制,表類型又稱為存儲引擎。
show engines; # 查看 MySQL 內的存儲引擎
但是我們創建表時并沒有指定存儲引擎吶。
因為 MySQL 默認的是:InnoDB
查詢表的存儲引擎
show create table student;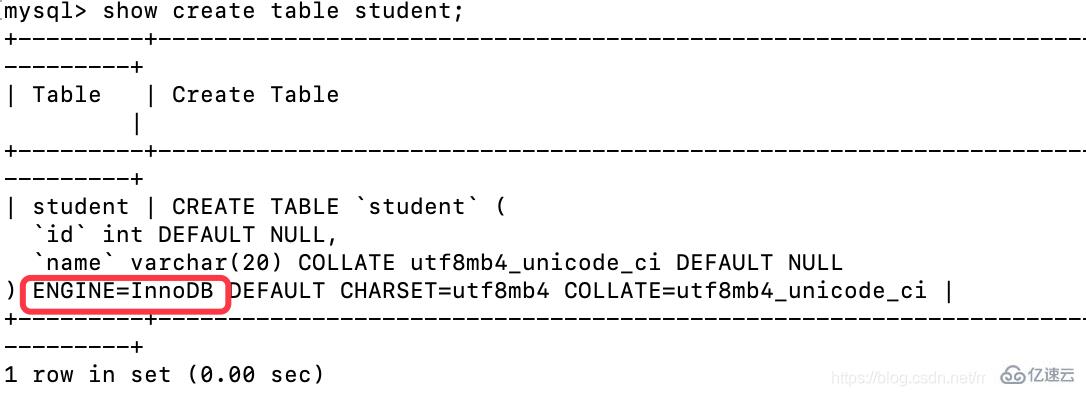
從上至下查看:
圖片來源:秋月
MySQL 架構總共四層,在上圖中以虛線作為劃分。
1、首先,最上層的服務并不是 MySQL 獨有的,大多數給予網絡的客戶端 / 服務器的工具或者服務都有類似的架構。比如:連接處理、授權認證、安全等。
2、第二層的架構包括大多數的 MySQL 的核心服務。包括:查詢解析、分析、優化、緩存以及所有的內置函數(例如:日期、時間、數學和加密函數)。同時,所有的跨存儲引擎的功能都在這一層實現:存儲過程、觸發器、視圖等。
3、第三層包含了存儲引擎。存儲引擎負責 MySQL 中數據的存儲和提取。服務器通過 API 和存儲引擎進行通信。這些接口屏蔽了不同存儲引擎之間的差異,使得這些差異對上層的查詢過程透明化。存儲引擎 API 包含十幾個底層函數,用于執行“開始一個事務”等操作。但存儲引擎一般不會去解析 SQL(InnoDB 會解析外鍵定義,因為其本身沒有實現該功能),不同存儲引擎之間也不會相互通信,而只是簡單的響應上層的服務器請求。
4、第四層包含了文件系統,所有的表結構和數據以及用戶操作的日志最終還是以文件的形式存儲在硬盤上。
MySQL 存儲引擎介紹:
InnoDB 存儲引擎
支持事務, 其設計目標主要面向聯機事務處理 (OLTP) 的應用。其
特點是行鎖設計、支持外鍵, 并支持類似 Oracle 的非鎖定讀, 即默認讀取操作不會產生鎖。 從 MySQL 5.5.8 版本開始是默認的存儲引擎。InnoDB 存儲引擎將數據放在一個邏輯的表空間中, 這個表空間就像黑盒一樣由 InnoDB 存儲引擎自身來管理。從 MySQL 4.1(包括 4.1)版本開始, 可以將每個 InnoDB 存儲引擎的 表單獨存放到一個獨立的 ibd 文件中。此外,InnoDB 存儲引擎支持將裸設備 (row disk) 用 于建立其表空間。InnoDB 通過使用多版本并發控制 (MVCC) 來獲得高并發性, 并且實現了 SQL 標準 的 4 種隔離級別, 默認為 REPEATABLE 級別, 同時使用一種稱為 netx-key locking 的策略來 避免幻讀 (phantom) 現象的產生。除此之外,InnoDB 存儲引擎還提供了插入緩沖(insert buffer)、二次寫(double write)、自適應哈希索引(adaptive hash index)、預讀(read ahead) 等高性能和高可用的功能。對于表中數據的存儲,InnoDB 存儲引擎采用了聚集 (clustered) 的方式, 每張表都是按 主鍵的順序進行存儲的, 如果沒有顯式地在表定義時指定主鍵,InnoDB 存儲引擎會為每一 行生成一個 6 字節的 ROWID, 并以此作為主鍵。InnoDB 存儲引擎是 MySQL 數據庫最為常用的一種引擎,Facebook、Google、Yahoo 等 公司的成功應用已經證明了 InnoDB 存儲引擎具備高可用性、高性能以及高可擴展性。對其 底層實現的掌握和理解也需要時間和技術的積累。如果想深入了解 InnoDB 存儲引擎的工作 原理、實現和應用, 可以參考《MySQL 技術內幕:InnoDB 存儲引擎》一書。MyISAM 存儲引擎
不支持事務、表鎖設計、支持全文索引, 主要面向一些 OLAP 數 據庫應用, 在 MySQL 5.5.8 版本之前是默認的存儲引擎 (除 Windows 版本外)。數據庫系統 與文件系統一個很大的不同在于對事務的支持,MyISAM 存儲引擎是不支持事務的。究其根 本, 這也并不難理解。用戶在所有的應用中是否都需要事務呢? 在數據倉庫中, 如果沒有 ETL 這些操作, 只是簡單地通過報表查詢還需要事務的支持嗎? 此外,MyISAM 存儲引擎的 另一個與眾不同的地方是, 它的緩沖池只緩存(cache) 索引文件, 而不緩存數據文件, 這與 大多數的數據庫都不相同。NDB 存儲引擎
2003 年,MySQL AB 公司從 Sony Ericsson 公司收購了 NDB 存儲引擎。 NDB 存儲引擎是一個集群存儲引擎, 類似于 Oracle 的 RAC 集群, 不過與 Oracle RAC 的 share everything 結構不同的是, 其結構是 share nothing 的集群架構, 因此能提供更高級別的 高可用性。NDB 存儲引擎的特點是數據全部放在內存中 (從 5.1 版本開始, 可以將非索引數 據放在磁盤上), 因此主鍵查找(primary key lookups) 的速度極快, 并且能夠在線添加 NDB 數據存儲節點 (data node) 以便線性地提高數據庫性能。由此可見,NDB 存儲引擎是高可用、 高性能、高可擴展性的數據庫集群系統, 其面向的也是 OLTP 的數據庫應用類型。Memory 存儲引擎
正如其名,Memory 存儲引擎中的數據都存放在內存中, 數據庫重 啟或發生崩潰, 表中的數據都將消失。它非常適合于存儲 OLTP 數據庫應用中臨時數據的臨時表, 也可以作為 OLAP 數據庫應用中數據倉庫的維度表。Memory 存儲引擎默認使用哈希 索引, 而不是通常熟悉的 B+ 樹索引。Infobright 存儲引擎
第三方的存儲引擎。其特點是存儲是按照列而非行的, 因此非常 適合 OLAP 的數據庫應用。其官方網站是 http://www.infobright.org/, 上面有不少成功的數據 倉庫案例可供分析。NTSE 存儲引擎
網易公司開發的面向其內部使用的存儲引擎。目前的版本不支持事務, 但提供壓縮、行級緩存等特性, 不久的將來會實現面向內存的事務支持。BLACKHOLE
黑洞存儲引擎,可以應用于主備復制中的分發主庫。
使用指定的存儲引擎,兩種方式:
1、創建表時指定
create table t2(id int)engine=innodb;2、修改 MySQL 配置文件
# /etc/my.cnf [mysqld]default-storage-engine=INNODBinnodb_file_per_table=1測試部分存儲引擎的效果,創建幾張表不同存儲引擎的表
create table t1(id int)engine=innodb;create table t2(id int)engine=myisam;create table t3(id int)engine=memory;create table t4(id int)engine=blackhole;注意:筆者安裝的 MySQL 版本在 8.0 以上
進入 MySQL 下面 data 找到對應庫下面,查看創建后的表文件類型

1.db.opt 文件:用來記錄該庫的默認字符集編碼和字符集排序規則用的。也就是說如果你創建數據庫指定默認字符集和排序規則,那么后續創建的表如果沒有指定字符集和排序規則,那么該新建的表將采用 db.opt 文件中指定的屬性。
2. 后綴名為.frm 的文件:這個文件主要是用來描述數據表結構 (id,name 字段等) 和字段長度等信息
3. 后綴名為.ibd 的文件:這個文件主要儲存的是采用獨立表儲存模式時儲存數據庫的數據信息和索引信息;
4. 后綴名為.MYD(MYData)的文件:從名字可以看出,這個是存儲數據庫數據信息的文件,主要是存儲采用獨立表儲存模式時存儲的數據信息;
5. 后綴名為.MYI 的文件:這個文件主要儲存的是數據庫的索引信息;
6.ibdata1 文件: 主要作用也是儲存數據信息和索引信息,這個文件在 mysql 安裝目錄的 data 文件夾下。
從上面可以看出,.ibd 儲存的是數據信息和索引信息,ibdata1 文件也是存儲數據信息和索引信息,.MYD 和.MYI 也是分別儲存數據信息和索引信息,那他們之間有什么區別呢?
主要區別是再于數據庫的存儲引擎不一樣,如果儲存引擎采用的是 MyISAM,則生成的數據文件為表名.frm、表名.MYD、表名的 MYI; 而儲存引擎如果是 innoDB,開啟了 innodb_file_per_table=1, 也就是采用獨立儲存的模式,生成的文件是表名.frm、表名.ibd,如果采用共存儲模式的,數據信息和索引信息都存儲在 ibdata1(在里面進行分類,從外面看是一個文件) 中;
在進行數據恢復的時候,如果用的是 MYISAM 數據引擎,那么數據很好恢復,只要將相應.frm, .MYD, .MYI 文件拷貝過去即可。但是如果是 innodb 的話,則每一個數據表都是一個單獨的文件,只將相應的.frm 和.ibd 文件拷貝過去是不夠的,必須在你的 ibd 文件的 tablespace id 和 ibdata1 文件中的元信息的 tablespace id 一致才可以。
演示向不同存儲引擎的表插入數據
insert t1 values(1);insert t2 values(2);insert t3 values(3);insert t4 values(4);t1:innodb、t2:myisam、t3:memory、t4:blackhole 存儲引擎
t3 的數據是存儲在內存中的,t4 寫入的數據會被丟到,因為是黑洞引擎
我們通過 select 都能查詢到內容,t4 怎么查詢都是空的,而 t3 在我們重啟 MySQL 服務后,內容就會被清空,因為它是存入內存中的,重啟等于釋放掉整個 MySQL 服務再開啟,
感謝各位的閱讀!關于“詳細分析 MySQL 數據庫的基礎用法”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
向 AI 問一下細節










