共計(jì) 2610 個(gè)字符,預(yù)計(jì)需要花費(fèi) 7 分鐘才能閱讀完成。
自動寫代碼機(jī)器人,免費(fèi)開通
這篇文章主要介紹 MySQL 查詢語句之復(fù)雜查詢的示例分析,文中介紹的非常詳細(xì),具有一定的參考價(jià)值,感興趣的小伙伴們一定要看完!
MySQL 是一種關(guān)系數(shù)據(jù)庫管理系統(tǒng),關(guān)系數(shù)據(jù)庫將數(shù)據(jù)保存在不同的表中,而不是將所有數(shù)據(jù)放在一個(gè)大倉庫內(nèi),這樣就增加了速度并提高了靈活性。在 MySQL 中經(jīng)常會有很多復(fù)雜的查詢,比如:
MySQL 復(fù)雜查詢
一、分組查詢:
1、關(guān)鍵字:GROUP
BY
2、用法:GROUP
BY 語句用于結(jié)合合計(jì)函數(shù) (比如 SUM),根據(jù)一個(gè)或多個(gè)列對結(jié)果集進(jìn)行分組, 合計(jì)函數(shù)常常需要添加
GROUP BY 語句。
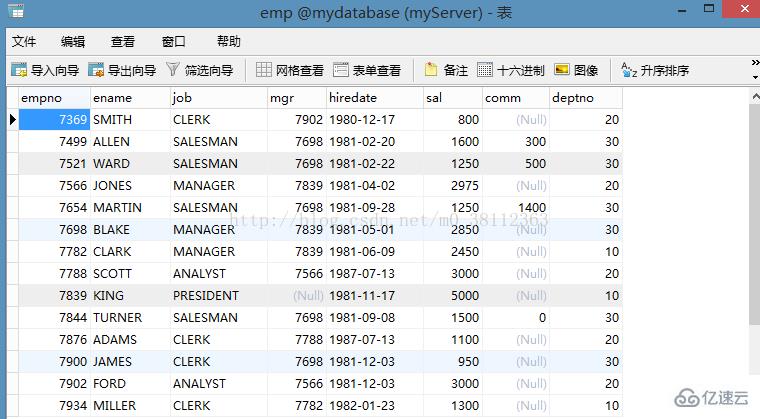
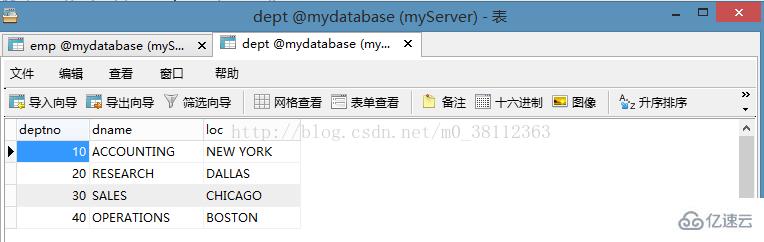
下面的給了兩張表 一張是 emp, 一張是 dept, 下面的查詢我們都對這兩張表進(jìn)行操作,如下圖:
第一張:emp 表
第二張:dept 表
現(xiàn)在我們查詢 emp 每個(gè)部門的工資總和, 語句如下:
SELECT deptno,SUM(sal)FROM emp GROUP BY deptno;
結(jié)果如下:

注:這里我們查詢每個(gè)部門的工資 (sal) 總和,所以應(yīng)該按照部門標(biāo)號 (deptno) 進(jìn)行分組,求和所以用了 sum();
3、having:
where 和 having 都是做條件判斷,在介紹 having 前我們看下 where 和 having 的區(qū)別
where 的作用是在對查詢結(jié)果進(jìn)行分組前,將不符合 where 條件的行去掉,即在分組之前過濾數(shù)據(jù),條件中不能包含聚合函數(shù),使用 where 條件顯示特定的行。
having 的作用是篩選滿足條件的組,即在分組之后過濾數(shù)據(jù),條件中經(jīng)常包含聚合函數(shù),使用 having條件顯示特定的組,也可以使用多個(gè)分組標(biāo)準(zhǔn)進(jìn)行分組。
例如: 我們要查詢 emp 表中工資總和大于 10000 的部門編號, 語句如下:
SELECT
deptno,SUM(sal)FROM emp GROUP BY deptno HAVING SUM(sal) 10000;
結(jié)果如下:

這樣就查出了工資總和大于 10000 的部門編號為 20,(為了理解也把工資總和顯示出來了)。
二、連表查詢:
根據(jù)兩個(gè)或多個(gè)表中的列之間的關(guān)系,從這些表中查詢數(shù)據(jù).
1、inner join(內(nèi)連接):
語法:select 字段名 1,字段名 2 from table1 [INNER] join table2 ON table1. 字段名 =table2. 字段名;
注: 內(nèi)連接是從結(jié)果中刪除其他被連接的表中沒有匹配行的所有行,只能查詢出連接的表中都擁有的信息,所以內(nèi)連接可能會丟失信息,還有 inner 可以省略。
例如: 我們連接 emp 和 dept 兩張表, 查詢 ename 和 deptno, 語句如下:
SELECT emp.ename,dept.deptno FROM emp INNER JOIN dept ON emp.deptno=dept.deptno;
還有種寫法:SELECT emp.ename,dept.deptno from emp,dept where emp.deptno=dept.deptno;
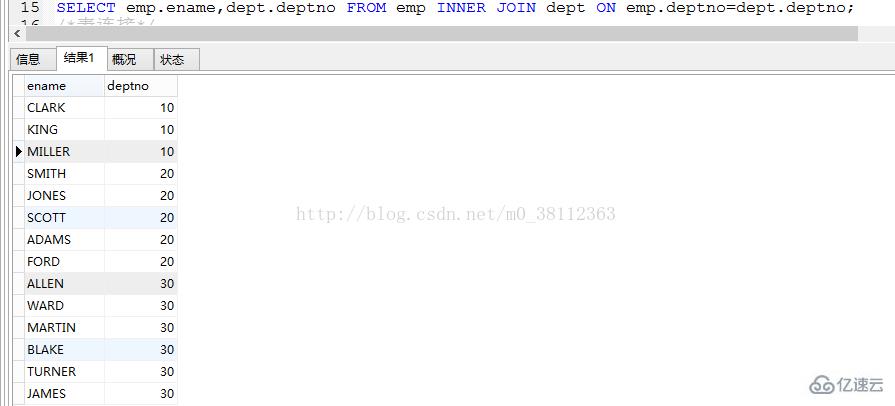
注意: 原來 dept 表中有 deptno 為 40 的, 但查詢出來就沒有了,這里是因?yàn)?emp 中 deptno 字段中沒有值為 40,所以使用 innner join 連接時(shí)就自動刪除了 dept 表中 deptno 字段值為 40 的記錄。
2、外連接:
2.1: 左外連接: 結(jié)果集保留左表的所有行,但只包含第二個(gè)表與第一表匹配的行。第二個(gè)表相應(yīng)的空行被放入 NULL 值。
2.2: 右外連接: 結(jié)果集保留右表的所有行,但只包含第二個(gè)表與第一表匹配的行。第二個(gè)表相應(yīng)的空行被放入 NULL 值。
左外連接和右外連接交換兩個(gè)表的位置就可以達(dá)到相同的效果。
現(xiàn)在我們進(jìn)行分組和連表一起用的查詢
例如: 我們要查詢 emp 每個(gè)部門的工資總和并且對應(yīng) dept 表中的部門名稱
解析這句話: 查詢的字段是 emp 中的每個(gè)部門 sal(工資總和),這里就要用到分組查詢, 但是還要查詢到對應(yīng)部門的部門名稱(dname),由于 dname
是在 dept 表中,所以就應(yīng)該連接 emp 和 dept 兩張表.
思路 1: 我們先查詢出我們需要的所有字段再進(jìn)行分組, 所以先連接再分組, 語句如下:
SELECT e.deptno,d.dname,SUM(e.sal) FROM emp e INNER JOIN dept d ON e.deptno=d.deptno GROUP BY d.deptno;)(注意這里使
用了別名 emp 的別名是 e,dept 的別名是 d)
第二種寫法:
SELECT e.deptno,d.dname,SUM(e.sal) FROM emp e,dept d WHEREe.deptno=d.deptno GROUP BY d.deptno;
這兩種寫法的結(jié)果都是一樣,如下:

思路 2:我們要查詢 emp 每個(gè)部門的工資總和,把這個(gè)結(jié)果集當(dāng)作一個(gè)表(這里稱為表 1),再讓表 1 去連接 dept 表查詢出對應(yīng)的部門名稱(dname);
分步 1:SELECT deptno,SUM(sal) FROM emp GROUP BY deptno; 這個(gè)語句就查詢出了 emp 表中每個(gè)部門的工資總和,現(xiàn)在我們再與 dept
表連接:
分步 2:SELECT xin.*,d.dname FROM(SELECT deptno,SUM(sal) FROM emp GROUP BY deptno) xin INNER JOIN dept d ON xin.deptno
=d.deptno; 這樣就查詢出了想要的結(jié)果, 注意這里的 xin 是別名,結(jié)果如下:

這里的代碼看起來很長,其實(shí)思路是很明確的,就是把第一個(gè)查詢結(jié)果當(dāng)作一張表去連接另一張表,這樣的思路不容易出錯(cuò),多練習(xí)寫起來就
很熟練了。
三、分頁:
關(guān)鍵字:LIMIT
語法:select * from tableName 條件 limit 當(dāng)前頁碼 * 頁面容量 -1 , 頁面容量;
一般 limit 都和 order by 連用
例如 我們要查詢 emp 表中按部門編號升序排列的 5 -10 的記錄,每頁顯示 5 條記錄, 語句如下:
SELECT *FROM emp ORDER BY deptno LIMIT 4,5;
這樣就可以查詢出想要的結(jié)果了,注意最后一個(gè)參數(shù) 5 是頁面容量,也就是本頁要顯示的行數(shù)(即本頁開始行到結(jié)束行的記錄條數(shù))。
比如我們要查詢 17 頁的記錄,每頁顯示 10 條記錄:
LIMIT 17*10-1,10;
四:IN
關(guān)鍵字:In
子查詢的返回值結(jié)果不只一個(gè)條件就必須用 IN 不能用 =
注:LIMIT 都是放在最后的。
以上是“MySQL 查詢語句之復(fù)雜查詢的示例分析”這篇文章的所有內(nèi)容,感謝各位的閱讀!希望分享的內(nèi)容對大家有幫助,更多相關(guān)知識,歡迎關(guān)注丸趣 TV 行業(yè)資訊頻道!
向 AI 問一下細(xì)節(jié)










