共計 2314 個字符,預(yù)計需要花費(fèi) 6 分鐘才能閱讀完成。
自動寫代碼機(jī)器人,免費(fèi)開通
丸趣 TV 小編給大家分享一下 MySQL 批量 SQL 插入的性能優(yōu)化示例,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討吧!
對于一些數(shù)據(jù)量較大的系統(tǒng),數(shù)據(jù)庫面臨的問題除了查詢效率低下,還有就是數(shù)據(jù)入庫時間長。特別像報表系統(tǒng),每天花費(fèi)在數(shù)據(jù)導(dǎo)入上的時間可能會長達(dá)幾個小時或十幾個小時之久。因此,優(yōu)化數(shù)據(jù)庫插入性能是很有意義的。
一條 SQL 語句插入多條數(shù)據(jù)
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES (0 , userid_0 , content_0 , 0);INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES (1 , userid_1 , content_1 , 1);INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES (0 , userid_0 , content_0 , 0), (1 , userid_1 , content_1 , 1);第二種 SQL 執(zhí)行效率高的主要原因是合并后日志量 [mysql 的 binlog 和 InnoDB 的事務(wù)讓日志] 減少了,降低日志刷盤的數(shù)據(jù)量和頻率,從而提高效率。
通過合并 SQL 語句,同時也能減少 SQL 語句解析的次數(shù),減少網(wǎng)絡(luò)傳輸?shù)?IO。
測試對比數(shù)據(jù),分別是單條數(shù)據(jù)的導(dǎo)入與轉(zhuǎn)換成一條 SQL 語句進(jìn)行導(dǎo)入。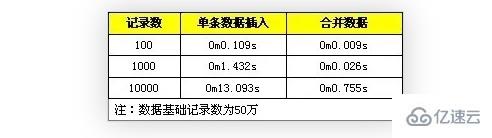
在事務(wù)中進(jìn)行插入處理
START TRANSACTION;INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES (0 , userid_0 , content_0 , 0);INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES (1 , userid_1 , content_1 , 1);...COMMIT;使用事務(wù)可以提高數(shù)據(jù)的插入效率,這是因為進(jìn)行一個 insert 操作時,MySQL 內(nèi)部都會建立一個事務(wù),在事務(wù)內(nèi)才進(jìn)行真正插入處理操作。
通過使用事務(wù)減少創(chuàng)建事務(wù)的消耗,所有插入都在執(zhí)行后才進(jìn)行提交操作
測試對比數(shù)據(jù),分筆試不適用事務(wù)和使用事務(wù)操作
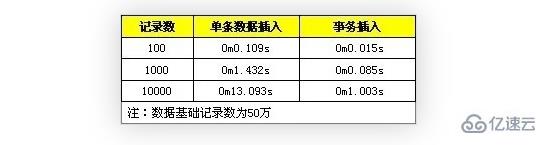
數(shù)據(jù)有序插入
數(shù)據(jù)有序的插入是插入記錄在主鍵上的有序排序
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES (1 , userid_1 , content_1 , 1);INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES (0 , userid_0 , content_0 , 0);INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES (2 , userid_2 , content_2 ,2);INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES (0 , userid_0 , content_0 , 0);INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES (1 , userid_1 , content_1 , 1);INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES (2 , userid_2 , content_2 ,2);由于數(shù)據(jù)庫插入時,需要維護(hù)索引數(shù)據(jù),無需的記錄會增大維護(hù)索引的成本。
參照 InnoDB 使用的 B +tree 索引,如果每次插入記錄都在索引的最后面,索引的定位效率很高,并且對索引調(diào)整較少;如果插入的記錄在索引中間,需要 B +tree 進(jìn)行分裂合并等處理,會消耗比較多計算資源,并且插入記錄的索引定位效率會下降,數(shù)據(jù)量較大時會有頻繁的磁盤操作。
測試對比數(shù)據(jù),隨機(jī)數(shù)據(jù)與順序數(shù)據(jù)的性能對比
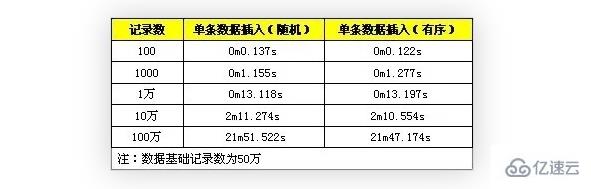
先刪除索引,插入完成后重建索引
性能綜合測試

合并數(shù)據(jù) + 事務(wù)的方法在較少數(shù)據(jù)量時,性能提升很明顯,數(shù)據(jù)量較大時,性能急劇下降,這是由于此時數(shù)據(jù)量超過了 innodb_buffer 的容量,每次定位索引涉及較多的磁盤讀寫操作,性能下降較快。
合并數(shù)據(jù) + 事務(wù) + 有序的方法在數(shù)據(jù)量達(dá)到千萬級以上表現(xiàn)依然良好,在數(shù)據(jù)量較大時,有序數(shù)據(jù)索引定位較為方便,不需要頻繁對磁盤進(jìn)行讀寫操作,可以維持較高
注意事項
SQL 語句是有長度限制,在進(jìn)行數(shù)據(jù)合并在同一 SQL 中務(wù)必不能超過 SQL 長度限制,通過 max_allowed_packet 配置可以修改,默認(rèn) 1M,測試時可以修改為 8M。
事務(wù)需要控制大小,事物太大可能影響執(zhí)行的效率。MySQL 有 innodb_log_buffer_size 配置項,超過這個值會把 innodb 的數(shù)據(jù)刷到磁盤中,這時,效率會有所下降。所以較好的做法是,在數(shù)據(jù)達(dá)到這個值前執(zhí)行事務(wù)提交。
看完了這篇文章,相信你對 MySQL 批量 SQL 插入的性能優(yōu)化示例有了一定的了解,想了解更多相關(guān)知識,歡迎關(guān)注丸趣 TV 行業(yè)資訊頻道,感謝各位的閱讀!
向 AI 問一下細(xì)節(jié)










