共計 2931 個字符,預計需要花費 8 分鐘才能閱讀完成。
自動寫代碼機器人,免費開通
這篇文章主要介紹怎么查詢 mysql 語句,文中介紹的非常詳細,具有一定的參考價值,感興趣的小伙伴們一定要看完!
查詢 mysql 語句的方法:查詢一張表中的記錄時,代碼為【select * from 表名 where name= long and age = 18】,from 后面加表名,where 后面是條件,select 后面是篩選出的字段。
查詢 mysql 語句的方法:
在 mysql 中 查詢一張表中的記錄的時候
書寫順序是: select * from 表名 where name= long and age = 18
但是 mysql 中的執行順序是
from 后面加表名 確定你是那張表
where 后面是條件 通過條件 來篩選這表的內容
select 后面是 你 where 篩選出的數據中的 某些字段 * 是所有字段
# 查詢語句執行的結果也是一張表,可以看成虛擬表
我們創建一張 emp 的員工表
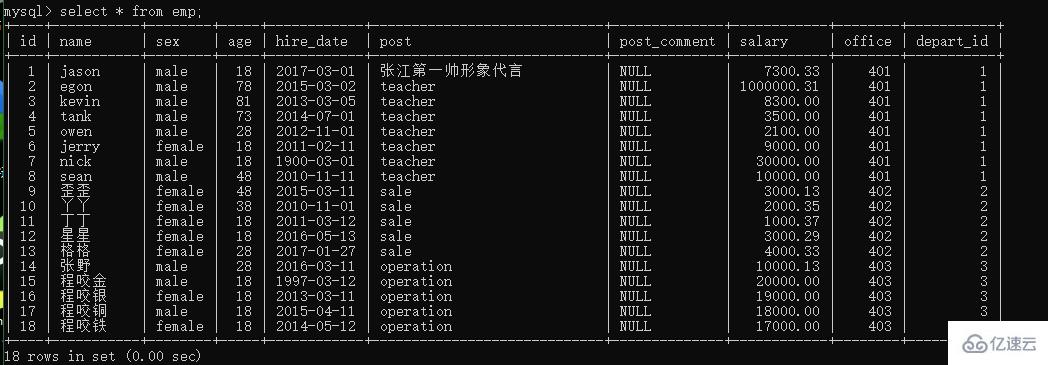
當我們的字段特別多的時候 結果的排版可能會出現凌亂現象 我們可以在查詢語句末尾 加上 \G 來規范查詢結果
select * from 表名 \G;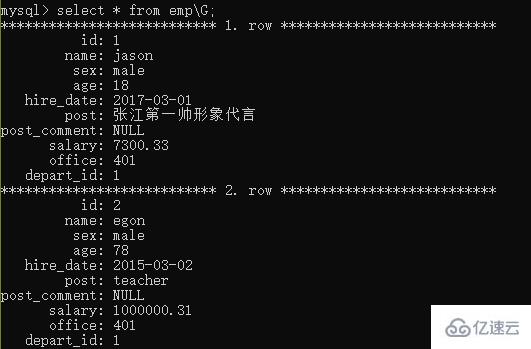
當我們遇到一個需求時 怎么來分析? 例如

1. 查詢 id 大于等于 3 小于等于 6 的數據
給你展示下實際操作 1. 先確定 來自哪一張表 from emp 2. 篩選條件 where id = 3 and id 3.select *
select * from emp where id = 3 and id = 6;
select * from emp where id between 3 and 6; between 等價于 id = 3 and id = 6
2. 查詢薪資是 20000 或者 18000 或者 17000 的數據
select id,name from emp where salary = 20000 or salary = 18000 or salary = 17000;
select id,name from emp where salary in (20000,18000,17000);3. 查詢員工姓名中包含 o 字母的員工姓名和薪資
模糊匹配 % 匹配多個任意字符 _ 匹配 一個任意字符
select name,salary from emp where name like %o%4. 查詢員工姓名是由四個字符組成的員工姓名與其薪資
select name, salary from emp where length(name) =4;
select name ,salary from emp where name like ____5. 查詢 id 小于 3 或者大于 6 的數據
select * from emp where id 3 or id
select * from emp where id not between 3 and 6;6. 查詢薪資不在 20000,18000,17000 范圍的數據
select * from emp where salary not in (20000,17000,18000);7. 查詢崗位描述為空的員工名與崗位名 針對 null 判斷的時候只能用 is 不能用 =
select name ,post from emp where post_comment is null;MySQL 對大小寫不敏感 平時寫的時候大小寫都可以
1、group by 分組
select * from emp group by post; # 按照部門分組
分組后 應該做到 最小單位是 組 , 而不應該是 展示 組內的單個數據信息
向上面那樣 他會直接給你 打印出來而沒有給你報錯 說明你的嚴格模沒有設置
show variables %mode% # 找到嚴格模式所在的地方 set session # 臨時有效 set global # 永久有效 set global sql_mode= strict_trans_tables # 設置字符類型的自動截取 set global sql_mode= strict_trans_tables,pad_char_to_full_length #char 取出時 取消自動去空格 set global sql_mode= strict_trans_tables,only_full_group_by # 設置分組后 最小單位是組

此時你如果還使用 select name from emp group by post; 就會報錯 #ERROR 1055 (42000): day37.emp.name isn t in GROUP BYselest 后應該接的是 你分組的字段名2、聚合函數(max, min ,sum,count, avg) 聚集到一起合成為一個結果
mysql 中 分組之后 只能拿到分組的字段信息 無法直接 獲取其他字段的信息 但是 你可以通過其他方法來間接的獲取(聚合函數)
獲取每個部門的最高工資
需求是 每一個部門 說明有分組 所以 先分組 在使用聚合函數來取值
select post ,max(salary) from emp group by post;每個部門的最低工資
select post,min(salary) emp group by post;
select post,min(salary) as 最小 from emp group by post;
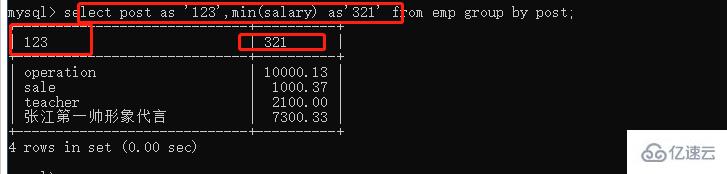
每個部門的平均工資
select post,avg(salary) from emp group by post;每個部門的工資總和
select post,sum(salary) from emp group by post;每個部門的人數
select post,count(age) from emp group by post;
select post,count(salary) from emp group by post;
select post,count(id) from emp group by post;
select post,count(post_comment) from emp group by post;
在統計分組內個數的時候 填寫任意非空字段都可以完成計數, 推薦使用能夠唯一標識數據的字段 比如 id 字段
聚合函數會自動將每一個分組內的單個數據做想要的計算, 無需你考慮
3、group_concat
查詢分組之后的部門名稱和每個部門下所有的學生姓
select post, group_concat(name) from emp group by post;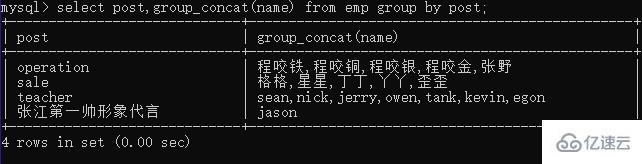
select post,group_concat(hahha ,name) from emp group by post;還可以拼接
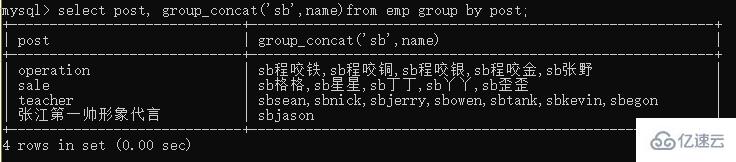
group_concat()能夠拿到分組后每一個數據指定字段 (可以是多個) 對應的值
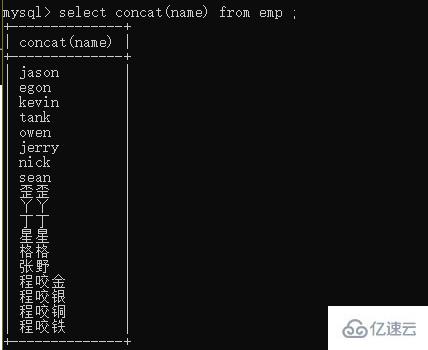
concat 就是用來幫你拼接數據
group_concat(分組之后用)
concat(不分組時用)
查詢每個員工的年薪
select name,salary*12 from emp;以上是“怎么查詢 mysql 語句”這篇文章的所有內容,感謝各位的閱讀!希望分享的內容對大家有幫助,更多相關知識,歡迎關注丸趣 TV 行業資訊頻道!
向 AI 問一下細節丸趣 TV 網 – 提供最優質的資源集合!











