共計 3243 個字符,預計需要花費 9 分鐘才能閱讀完成。
自動寫代碼機器人,免費開通
丸趣 TV 小編給大家分享一下 InnoDB 的插入緩沖方法,希望大家閱讀完這篇文章后大所收獲,下面讓我們一起去探討吧!
InnoDB 引擎有幾個重點特性,為其帶來了更好的性能和可靠性:
插入緩沖(Insert Buffer)兩次寫(Double Write)自適應哈希索引(Adaptive Hash Index)異步 IO(Async IO)刷新鄰接頁(Flush Neighbor Page)
今天我們的主題就是 插入緩沖(Insert Buffer), 由于 InnoDB 引擎底層數據存儲結構式 B + 樹,而對于索引我們又有聚集索引和非聚集索引。
在進行數據插入時必然會引起索引的變化,聚集索引不必說,一般都是遞增有序的。而非聚集索引就不一定是什么數據了,其離散性導致了在插入時結構的不斷變化,從而導致插入性能降低。
所以為了解決非聚集索引插入性能的問題,InnoDB 引擎 創造了 Insert Buffer。
Insert Buffer 的存儲
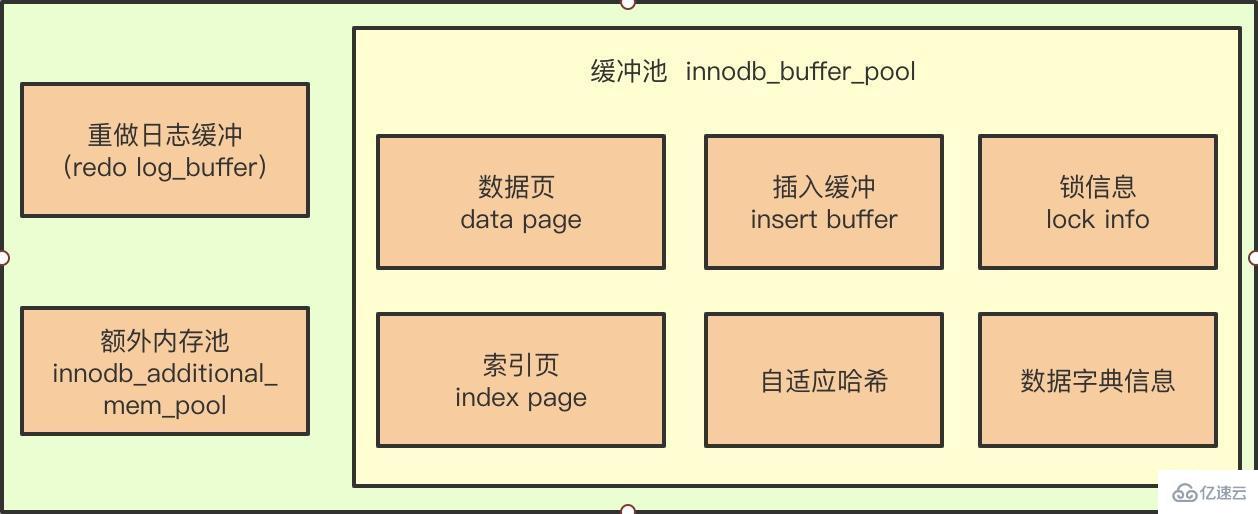
看到上圖,可能大家會認為 Insert Buffer 就是 InnoDB 緩沖池的一個組成部分。
** 重點:** 其實對也不對,InnoDB 緩沖池確實包含了 Insert Buffer 的信息,但 Insert Buffer 其實和數據頁一樣,也是物理存在的(以 B + 樹的形式存在共享表空間中)。
Insert Buffer 的作用
先說幾個點:
一張表只能有一個主鍵索引,那是因為其物理存儲是一個 B + 樹。(別忘了聚集索引葉子節點存儲的數據,而數據只有一份)
非聚集索引葉子節點存的是聚集索引的主鍵

聚集索引的插入
首先我們知道在 InnoDB 存儲引擎中,主鍵是行唯一的標識符(也就是我們常叨叨的聚集索引)。我們平時插入數據一般都是按照主鍵遞增插入,因此聚集索引都是順序的,不需要磁盤的隨機讀取。
比如表:
CREATE TABLE test(
id INT AUTO_INCREMENT,
name VARCHAR(30),
PRIMARY KEY(id)
); 復制代碼
如上我創建了一個主鍵 id, 它有以下的特性:
Id 列是自增長的 Id 列插入 NULL 值時,由于 AUTO_INCREMENT 的原因,其值會遞增同時數據頁中的行記錄按 id 的值進行順序存放
一般情況下由于聚集索引的有序性,不需要隨機讀取頁中的數據,因為此類的順序插入速度是非常快的。
但如果你把列 Id 插入 UUID 這種數據,那你插入就是和非聚集索引一樣都是隨機的了。會導致你的 B + tree 結構不停地變化,那性能必然會受到影響。
非聚集索引的插入
很多時候我們的表還會有很多非聚集索引,比如我按照 b 字段查詢,且 b 字段不是唯一的。如下表:
CREATE TABLE test(
id INT AUTO_INCREMENT,
name VARCHAR(30),
PRIMARY KEY(id),
KEY(name)
); 復制代碼 這里我創建了一個 x 表,它有以下特點:
有一個聚集索引 id 有一個不唯一的非聚集索引 name 在插入數據時數據頁是按照主鍵 id 進行順序存放輔助索引 name 的數據插入不是順序的
非聚集索引也是一顆 B + 樹,只是葉子節點存的是聚集索引的主鍵和 name 的值。
因為不能保證 name 列的數據是順序的,所以非聚集索引這棵樹的插入必然也不是順序的了。
當然如果 name 列插入的是時間類型數據,那其非聚集索引的插入也是順序的。
Insert Buffer 的到來
可以看出非聚集索引插入的離散性導致了插入性能的下降,因此 InnoDB 引擎設計了 Insert Buffer 來提高插入性能。
我來看看使用 Insert Buffer 是怎么插入的:

首先對于非聚集索引的插入或更新操作,不是每一次直接插入到索引頁中,而是先判斷插入的非聚集索引頁是否在緩沖池中。
若在,則直接插入;若不在,則先放入到一個 Insert Buffer 對象中。
給外部的感覺好像是樹已經插入非聚集的索引的葉子節點,而其實是存放在其他位置了
以一定的頻率和情況進行 Insert Buffer 和輔助索引頁子節點的 merge(合并)操作,通常會將多個插入操作一起進行 merge,這就大大的提升了非聚集索引的插入性能。
Insert Buffer 的使用要求:索引是非聚集索引索引不是唯一(unique)的
只有滿足上面兩個必要條件時,InnoDB 存儲引擎才會使用 Insert Buffer 來提高插入性能。
那為什么必須滿足上面兩個條件呢?
第一點索引是非聚集索引就不用說了,人家聚集索引本來就是順序的也不需要你
第二點必須不是唯一(unique)的,因為在寫入 Insert Buffer 時,數據庫并不會去判斷插入記錄的唯一性。如果再去查找肯定又是離散讀取的情況了,這樣 InsertBuffer 就失去了意義。
Insert Buffer 信息查看
我們可以使用命令 SHOW ENGINE INNODB STATUS 來查看 Insert Buffer 的信息:
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 7545, free list len 3790, seg size 11336,
8075308 inserts,7540969 merged sec, 2246304 merges
... 復制代碼
使用命令后,我們會看到很多信息,這里我們只看下 INSERT BUFFER 的:
seg size 代表當前 Insert Buffer 的大小 11336*16KB
free listlen 代表了空閑列表的長度
size 代表了已經合并記錄頁的數量
Inserts 代表了插入的記錄數
merged recs 代表了合并的插入記錄數量
merges 代表合并的次數,也就是實際讀取頁的次數
merges:merged recs 大約為 1∶3,代表了 Insert Buffer 將對于非聚集索引頁的離散 IO 邏輯請求大約降低了 2 /3
Insert Buffer 的問題
說了這么多針對于 Insert Buffer 的好處,但目前 Insert Buffer 也存在一個問題:
即在寫密集的情況下,插入緩沖會占用過多的緩沖池內存(innodb_buffer_pool),默認最大可以占用到 1 / 2 的緩沖池內存。
占用了過大的緩沖池必然會對其他緩沖池操作帶來影響
Insert Buffer 的優化
MySQL5.5 之前的版本中其實都叫做 Insert Buffer,之后優化為 Change Buffer 可以看做是 Insert Buffer 的升級版。
插入緩沖(Insert Buffer)這個其實只針對 INSERT 操作做了緩沖,而 Change Buffer 對 INSERT、DELETE、UPDATE 都進行了緩沖,所以可以統稱為寫緩沖,其可以分為:
Insert Buffer
Delete Buffer
Purgebuffer
總結:
Insert Buffer 到底是個什么?
其實 Insert Buffer 的數據結構就是一棵 B + 樹。
在 MySQL 4.1 之前的版本中每張表有一棵 Insert Buffer B+ 樹
目前版本是全局只有一棵 Insert Buffer B+ 樹,負責對所有的表的輔助索引進行 Insert Buffer
這棵 B + 樹存放在共享表空間 ibdata1 中
以下幾種情況下 Insert Buffer 會寫入真正非聚集索引,也就是所說的 Merge Insert Buffer
當輔助索引頁被讀取到緩沖池中時 Insert Buffer Bitmap 頁追蹤到該輔助索引頁已無可用空間時 Master Thread 線程中每秒或每 10 秒會進行一次 Merge Insert Buffer 的操作
一句話概括下:
Insert Buffer 就是用于提升非聚集索引頁的插入性能的,其數據結構類似于數據頁的一個 B + 樹,物理存儲在共享表空間 ibdata1 中。
看完了這篇文章,相信你對 InnoDB 的插入緩沖方法有了一定的了解,想了解更多相關知識,歡迎關注丸趣 TV 行業資訊頻道,感謝各位的閱讀!
向 AI 問一下細節
丸趣 TV 網 – 提供最優質的資源集合!











