共計(jì) 4299 個(gè)字符,預(yù)計(jì)需要花費(fèi) 11 分鐘才能閱讀完成。
這篇文章主要講解了“mysql innodb 指的是什么”,文中的講解內(nèi)容簡(jiǎn)單清晰,易于學(xué)習(xí)與理解,下面請(qǐng)大家跟著丸趣 TV 小編的思路慢慢深入,一起來(lái)研究和學(xué)習(xí)“mysql innodb 指的是什么”吧!
InnoDB 是 MySQL 的數(shù)據(jù)庫(kù)引擎之一,現(xiàn)為 MySQL 的默認(rèn)存儲(chǔ)引擎,為 MySQL AB 發(fā)布 binary 的標(biāo)準(zhǔn)之一;InnoDB 采用雙軌制授權(quán),一個(gè)是 GPL 授權(quán),另一個(gè)是專有軟件授權(quán)。InnoDB 是事務(wù)型數(shù)據(jù)庫(kù)的首選引擎,支持事務(wù)安全表(ACID);InnoDB 支持行級(jí)鎖,行級(jí)鎖可以最大程度的支持并發(fā),行級(jí)鎖是由存儲(chǔ)引擎層實(shí)現(xiàn)的。
如果想看自己的數(shù)據(jù)庫(kù)默認(rèn)使用的那個(gè)存儲(chǔ)引擎,可以通過(guò)使用命令 SHOW VARIABLES LIKE storage_engine
一、InnoDB 存儲(chǔ)引擎
InnoDB,是 MySQL 的數(shù)據(jù)庫(kù)引擎之一,現(xiàn)為 MySQL 的默認(rèn)存儲(chǔ)引擎,為 MySQL AB 發(fā)布 binary 的標(biāo)準(zhǔn)之一。InnoDB 由 Innobase Oy 公司所開發(fā),2006 年五月時(shí)由甲骨文公司并購(gòu)。與傳統(tǒng)的 ISAM 與 MyISAM 相比,InnoDB 的最大特色就是支持了 ACID 兼容的事務(wù)(Transaction)功能,類似于 PostgreSQL。
InnoDB 采用雙軌制授權(quán),一個(gè)是 GPL 授權(quán),另一個(gè)是專有軟件授權(quán)。
1、InnoDB 是事務(wù)型數(shù)據(jù)庫(kù)的首選引擎,支持事務(wù)安全表(ACID)
事務(wù)的 ACID 屬性:即原子性、一致性、隔離性、持久性
a. 原子性:原子性也就是說(shuō)這組語(yǔ)句要么全部執(zhí)行,要么全部不執(zhí)行,如果事務(wù)執(zhí)行到一半出現(xiàn)錯(cuò)誤,數(shù)據(jù)庫(kù)就要回滾到事務(wù)開始執(zhí)行的地方。
實(shí)現(xiàn):主要是基于 MySQ 日志系統(tǒng)的 redo 和 undo 機(jī)制。事務(wù)是一組 SQL 語(yǔ)句,里面有選擇,查詢、刪除等功能。每條語(yǔ)句執(zhí)行會(huì)有一個(gè)節(jié)點(diǎn)。例如,刪除語(yǔ)句執(zhí)行后,在事務(wù)中有個(gè)記錄保存下來(lái),這個(gè)記錄中儲(chǔ)存了我們什么時(shí)候做了什么事。如果出錯(cuò)了,就會(huì)回滾到原來(lái)的位置,redo 里面已經(jīng)存儲(chǔ)了我做過(guò)什么事了,然后逆向執(zhí)行一遍就可以了。
b. 一致性:事務(wù)開始前和結(jié)束后,數(shù)據(jù)庫(kù)的完整性約束沒(méi)有被破壞。(eg: 比如 A 向 B 轉(zhuǎn)賬,不可能 A 扣了錢,B 卻沒(méi)有收到)
c. 隔離性:同一時(shí)間,只允許一個(gè)事務(wù)請(qǐng)求同一數(shù)據(jù),不同的事務(wù)之間彼此沒(méi)有任何干擾;
如果不考慮隔離性則會(huì)出現(xiàn)幾個(gè)問(wèn)題:
i、臟讀:是指在一個(gè)事務(wù)處理過(guò)程里讀取了另一個(gè)未提交的事務(wù)中的數(shù)據(jù)(當(dāng)一個(gè)事務(wù)正在多次修改某個(gè)數(shù)據(jù),而在這個(gè)事務(wù)中這多次的修改都還未提交,這時(shí)一個(gè)并發(fā)的事務(wù)來(lái)訪問(wèn)該數(shù)據(jù),就會(huì)造成兩個(gè)事務(wù)得到的數(shù)據(jù)不一致);(讀取了另一個(gè)事務(wù)未提交的臟數(shù)據(jù))
ii、不可重復(fù)讀:在對(duì)于數(shù)據(jù)庫(kù)中的某個(gè)數(shù)據(jù),一個(gè)事務(wù)范圍內(nèi)多次查詢卻返回了不同的數(shù)據(jù)值,這是由于在查詢間隔,被另一個(gè)事務(wù)修改并提交了;(讀取了前一個(gè)事務(wù)提交的數(shù)據(jù),查詢的都是同一個(gè)數(shù)據(jù)項(xiàng))
iii、虛讀(幻讀):是事務(wù)非獨(dú)立執(zhí)行時(shí)發(fā)生的一種現(xiàn)象(eg: 事務(wù) T1 對(duì)一個(gè)表中所有的行的某個(gè)數(shù)據(jù)項(xiàng)做了從“1”修改為“2”的操作,這時(shí)事務(wù) T2 又對(duì)這個(gè)表中插入了一行數(shù)據(jù)項(xiàng),而這個(gè)數(shù)據(jù)項(xiàng)的數(shù)值還是為“1”并且提交給數(shù)據(jù)庫(kù)。而操作事務(wù) T1 的用戶如果再查看剛剛修改的數(shù)據(jù),會(huì)發(fā)現(xiàn)還有一行沒(méi)有修改,其實(shí)這行是從事務(wù) T2 中添加的,就好像產(chǎn)生幻覺(jué)一樣);(讀取了前一個(gè)事務(wù)提交的數(shù)據(jù),針對(duì)一批數(shù)據(jù)整體)
d. 持久性:事務(wù)完成后,事務(wù)對(duì)數(shù)據(jù)庫(kù)的所有更新將被保存到數(shù)據(jù)庫(kù),不能回滾
2、InnoDB 是 mySQL 默認(rèn)的存儲(chǔ)引擎,默認(rèn)的隔離級(jí)別是 RR,并且在 RR 的隔離級(jí)別下更近一步,通過(guò)多版本并發(fā)控制(MVCC)解決不可重復(fù)讀問(wèn)題,加上間隙鎖(也就是并發(fā)控制)解決幻讀問(wèn)題。因此 InnoDB 的 RR 隔離級(jí)別其實(shí)實(shí)現(xiàn)了串行化級(jí)別的效果,而保留了比較好的并發(fā)性能。
MySQL 數(shù)據(jù)庫(kù)為我們提供的四種隔離級(jí)別:
a、Serializable(串行化):可避免臟讀、不可重復(fù)讀、幻讀的發(fā)生;
b、Repeatable read(可重復(fù)讀):可避免臟讀、不可重復(fù)讀的發(fā)生;
c、Read committed(讀已提交):可避免臟讀的發(fā)生;
d、Read uncommitted(讀未提交):最低級(jí)別,任何情況都無(wú)法保證;
從 a —- d 隔離級(jí)別由高到低,級(jí)別越高,執(zhí)行效率越低
3、InnoDB 支持行級(jí)鎖。行級(jí)鎖可以最大程度的支持并發(fā),行級(jí)鎖是由存儲(chǔ)引擎層實(shí)現(xiàn)的。
鎖:鎖的主要作用是管理共享資源的并發(fā)訪問(wèn),用于實(shí)現(xiàn)事務(wù)的隔離性
類型:共享鎖(讀鎖)、獨(dú)占鎖(寫鎖 )
MySQL 鎖的力度:表級(jí)鎖(開銷小、并發(fā)性低),通常在服務(wù)器層實(shí)現(xiàn)
行級(jí)鎖(開銷大、并發(fā)性高),只會(huì)在存儲(chǔ)引擎層面進(jìn)行實(shí)現(xiàn)
4、InnoDB 是為處理巨大數(shù)據(jù)量的最大性能設(shè)計(jì)。它的 CPU 效率可能是任何基于磁盤的關(guān)系型數(shù)據(jù)庫(kù)引擎所不能匹敵的
5、InnoDB 存儲(chǔ)引擎完全與 MySQL 服務(wù)器整合,InnoDB 存儲(chǔ)引擎為在主內(nèi)存中緩存數(shù)據(jù)和索引而維持它自己的緩沖池。InnoDB 將它的表和索引在一個(gè)邏輯表空間中,表空間可以包含數(shù)個(gè)文件(或原始磁盤文件);
6、InnoDB 支持外鍵完整性約束,存儲(chǔ)表中的數(shù)據(jù)時(shí),每張表的存儲(chǔ)都按照主鍵順序存放,如果沒(méi)有顯示在表定義時(shí)指定主鍵。InnoDB 會(huì)為每一行生成一個(gè) 6 字節(jié)的 ROWID, 并以此作為主鍵
7、InnoDB 被用在眾多需要高性能的大型數(shù)據(jù)庫(kù)站點(diǎn)上
8、InnoDB 中不保存表的行數(shù)(eg:select count(*)from table 時(shí),InnoDB 需要掃描一遍整個(gè)表來(lái)計(jì)算有多少行);清空整個(gè)表時(shí),InnoDB 是一行一行的刪除,效率非常慢;
InnoDB 不創(chuàng)建目錄,使用 InnoDB 時(shí),MySQL 將在 MySQL 數(shù)據(jù)目錄下創(chuàng)建一個(gè)名為 ibdata1 的 10MB 大小的自動(dòng)擴(kuò)展數(shù)據(jù)文件,以及兩個(gè)名為 ib_logfile0 和 ib_logfile1 的 5MB 大小的日志文件
二、InnoDB 引擎的底層實(shí)現(xiàn)
InnoDB 的存儲(chǔ)文件有兩個(gè),后綴名分別是 .frm 和 .idb;其中 .frm 是表的定義文件,.idb 是表的數(shù)據(jù)文件。
1、InnoDB 引擎采用 B +Tree 結(jié)構(gòu)來(lái)作為索引結(jié)構(gòu)
B-Tree(平衡多路查找樹):為磁盤等外存儲(chǔ)設(shè)備設(shè)計(jì)的一種平衡查找樹
系統(tǒng)從磁盤讀取數(shù)據(jù)到內(nèi)存時(shí)是以磁盤塊位基本單位的,位于同一磁盤塊中的數(shù)據(jù)會(huì)被一次性讀取出來(lái),而不是按需讀取。
InnoDB 存儲(chǔ)引擎使用頁(yè)作為數(shù)據(jù)讀取單位,頁(yè)是其磁盤管理的最小單位,默認(rèn) page 大小是 16k.
系統(tǒng)的一個(gè)磁盤塊的存儲(chǔ)空間往往沒(méi)有那么大,因此 InnoDB 每次申請(qǐng)磁盤空間時(shí)都會(huì)是若干地址連續(xù)磁盤塊來(lái)達(dá)到頁(yè)的大小 16KB。
InnoDB 在把磁盤數(shù)據(jù)讀入到磁盤時(shí)會(huì)以頁(yè)為基本單位,在查詢數(shù)據(jù)時(shí),如果一個(gè)頁(yè)中的每條數(shù)據(jù)都能助于定位數(shù)據(jù)記錄的位置,這將會(huì)減少磁盤 I / O 的次數(shù),提高查詢效率。
B-Tree 結(jié)構(gòu)的數(shù)據(jù)可以讓系統(tǒng)高效的找到數(shù)據(jù)所在的磁盤塊
B-Tree 中的每個(gè)節(jié)點(diǎn)根據(jù)實(shí)際情況可以包含大量的關(guān)鍵字信息和分支,例:
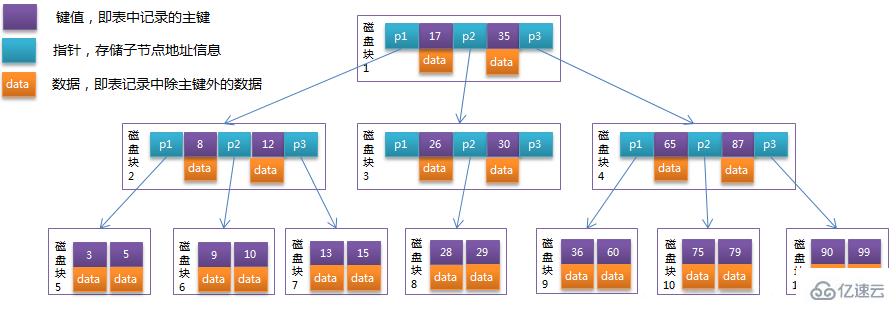
每個(gè)節(jié)點(diǎn)占用一個(gè)盤塊的磁盤空間,一個(gè)節(jié)點(diǎn)上有兩個(gè)升序排序的關(guān)鍵字和三個(gè)指向子樹根節(jié)點(diǎn)的指針,指針存儲(chǔ)的是子節(jié)點(diǎn)所在磁盤塊的地址。
以根節(jié)點(diǎn)為例,關(guān)鍵字為 17 和 35,P1 指針指向的子樹的數(shù)據(jù)范圍小于 17,P2 指針指向的子樹的數(shù)據(jù)范圍為 17—-35,P3 指針指向的子樹的數(shù)據(jù)范圍大于 35;
模擬查找關(guān)鍵字 29 的過(guò)程:
a. 根據(jù)根節(jié)點(diǎn)找到磁盤塊 1,讀入內(nèi)存。【磁盤 I / O 操作第一次】
b. 比較關(guān)鍵字 29 在區(qū)間(17,35),找到磁盤塊 1 的指針 P2;
c. 根據(jù) P2 指針找到磁盤塊 3,讀入內(nèi)存。【磁盤 I / O 操作第二次】
d. 比較關(guān)鍵字 29 在區(qū)間(26,30),找到磁盤塊 3 的指針 P2;
e. 根據(jù) P2 指針找到磁盤塊 8,讀入內(nèi)存。【磁盤 I / O 操作第三次】
f. 在磁盤塊 8 中的關(guān)鍵字列表中找到關(guān)鍵字 29.
MySQL 的 InnoDB 存儲(chǔ)引擎在設(shè)計(jì)時(shí)是將根節(jié)點(diǎn)常駐內(nèi)存的,因此力求達(dá)到樹的深度不超過(guò) 3,也就是 I / O 不需要超過(guò)三次;
分析上面的結(jié)果,發(fā)現(xiàn)需要三次磁盤 I / O 操作,和三次內(nèi)存查找操作。由于內(nèi)存中的關(guān)鍵字是一個(gè)有序表結(jié)構(gòu),可以利用二分法查找提高效率;而三次磁盤 I / O 操作時(shí)影響整個(gè) B -Tree 查找效率的決定因素。
B+Tree
B+Tree 是在 B -Tree 基礎(chǔ)上的一種優(yōu)化,使其更適合實(shí)現(xiàn)外存儲(chǔ)索引結(jié)構(gòu),B-Tree 中每個(gè)節(jié)點(diǎn)中有 key,也有 data,而每一頁(yè)的存儲(chǔ)空間是有限的,如果 data 數(shù)據(jù)較大時(shí)將會(huì)導(dǎo)致每個(gè)節(jié)點(diǎn)(即一個(gè)頁(yè))能存儲(chǔ)的 key 的數(shù)量很小。當(dāng)存儲(chǔ)的數(shù)據(jù)量很大時(shí)同樣會(huì)導(dǎo)致 B -Tree 的深度較大,增大查詢時(shí)的磁盤 I / O 次數(shù),進(jìn)而影響查詢效率。
在 B +Tree 中所有數(shù)據(jù)記錄節(jié)點(diǎn)都是按照鍵值大小順序存放在同一層的葉子節(jié)點(diǎn)上,而非葉子節(jié)點(diǎn)上只存儲(chǔ) key 值信息,這樣可以大大加大每個(gè)節(jié)點(diǎn)存儲(chǔ)的 key 值數(shù)量,降低 B +Tree 的高度;
B+Tree 在 B -Tree 的基礎(chǔ)上有兩點(diǎn)變化:(1)數(shù)據(jù)是存在葉子節(jié)點(diǎn)中的
(2)數(shù)據(jù)節(jié)點(diǎn)之間是有指針指向的
由于 B +Tree 的非葉子節(jié)點(diǎn)只存儲(chǔ)鍵值信息,假設(shè)每個(gè)磁盤塊能存儲(chǔ) 4 個(gè)鍵值及指針信息,則變成 B +Tree 后其結(jié)構(gòu)如下圖所示:
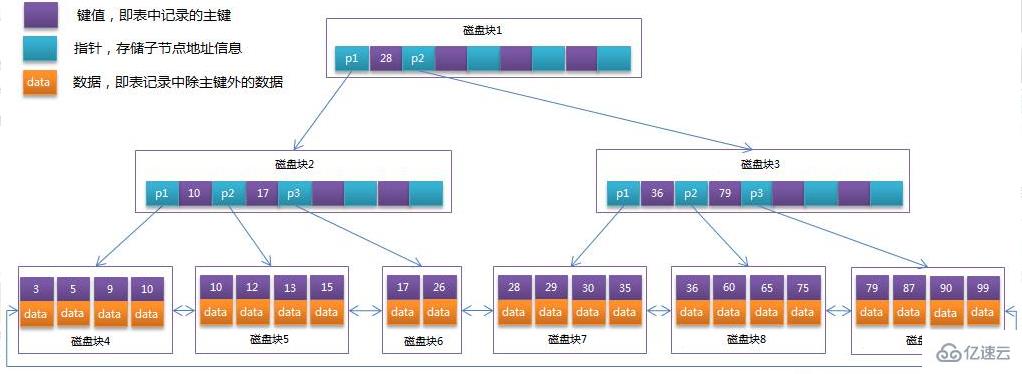
通常在 B +Tree 上有兩個(gè)頭指針,一個(gè)指向根節(jié)點(diǎn),另一個(gè)指向關(guān)鍵字最小的葉子節(jié)點(diǎn),而且所有葉子節(jié)點(diǎn)(即數(shù)據(jù)節(jié)點(diǎn))之間是一種鏈?zhǔn)江h(huán)結(jié)構(gòu)。
因此可以對(duì) B +Tree 進(jìn)行兩種查找運(yùn)算,一種是對(duì)于主鍵的范圍查找和分頁(yè)查找,另一種是從根節(jié)點(diǎn)開始,進(jìn)行隨機(jī)查找。
InnoDB 中的 B +Tree
InnoDB 是以 ID 為索引的數(shù)據(jù)存儲(chǔ)
采用 InnoDB 引擎的數(shù)據(jù)存儲(chǔ)文件有兩個(gè),一個(gè)定義文件,一個(gè)是數(shù)據(jù)文件。
InnoDB 通過(guò) B +Tree 結(jié)構(gòu)對(duì) ID 建索引,然后在葉子節(jié)點(diǎn)中存儲(chǔ)記錄
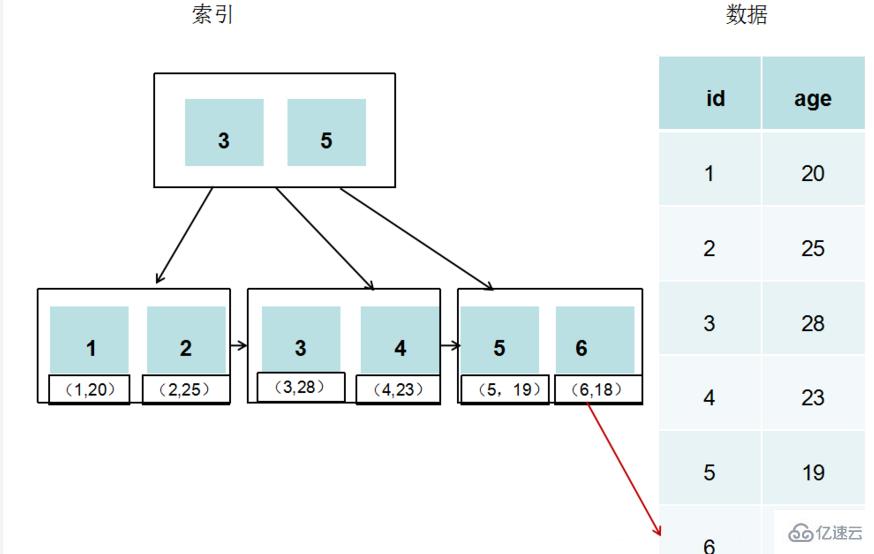
若建立索引的字段不是主鍵 ID,則對(duì)該字段建索引,然后在葉子節(jié)點(diǎn)中存儲(chǔ)的是該記錄的主鍵,然后通過(guò)主鍵索引找到對(duì)應(yīng)記錄。
感謝各位的閱讀,以上就是“mysql innodb 指的是什么”的內(nèi)容了,經(jīng)過(guò)本文的學(xué)習(xí)后,相信大家對(duì) mysql innodb 指的是什么這一問(wèn)題有了更深刻的體會(huì),具體使用情況還需要大家實(shí)踐驗(yàn)證。這里是丸趣 TV,丸趣 TV 小編將為大家推送更多相關(guān)知識(shí)點(diǎn)的文章,歡迎關(guān)注!
向 AI 問(wèn)一下細(xì)節(jié)丸趣 TV 網(wǎng) – 提供最優(yōu)質(zhì)的資源集合!











