共計 4352 個字符,預計需要花費 11 分鐘才能閱讀完成。
丸趣 TV 小編給大家分享一下 PostgreSQL 如何實現并行查詢,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
并行查詢的背景
隨著 SSD 等磁盤技術的平民化,以及動輒上百 GB 內存的普及,I/ O 層面的性能問題得到了有效緩解。提升數據庫的擴展性能,可以追求 Scale Out 的方式,增加機器,往分布式方向發展,也可以追求 Scale Up,增加硬件組件,充分利用各個硬件的資源,把單機的性能發揮到最大效果。相較而言,Scale Up 通過軟件加速性能,依賴軟件層面的優化,是低成本的擴展方案。
現代服務器除了磁盤和內存資源的增強,多 CPU 的配置也足夠強大。數據庫的 Join、聚合等操作內存耗費比較大,很多時間花在了數據的交換和緩存上,CPU 的利用率并不高,所以面向 CPU 的加速策略中,并發執行是一種常見的方法。
查詢的性能是評價 OLAP 型數據庫產品好壞的核心指標,而并行查詢可以聚焦在數據的讀和計算上,通過把 Join、聚合、排序等操作分解成多個操作實現并行。
并行查詢的挑戰在于,為了要做并行而加入的數據分片過程、進程或線程間的通信,以及并發控制方面帶來的系統開銷不但沒有增加性能,反而降低了原有性能。實現上,如何在優化器里規劃好并行計劃也是很多數據庫做不到的。
PostgreSQL 的并行查詢功能主要由 PostgreSQL 社區的核心開發者 Robert Haas 等人開發。從 Robert Haas 的個人博客了解到,社區開發 PostgreSQL 的并行查詢特性時間表如下:
2013 年 10 月,執行框架上做了 Dynamic Background Workers 和 Dynamic Shared Memory 兩個調整
2014 年 12 月,Amit Kapila 提交了一個簡單版的 parallel sequential scan 的 patch;
2015 年 3 月,正式版的 parallel sequential scan 的 patch 被提交;
2016 年 3 月,支持 parallel joins 和 parallel aggregation;
2016 年 4 月,作為 9.6 的新特性發布。
PostgreSQL 的并行查詢在大數據量(中間結果在 GB 以上)的 Join、Merge 場合,效果比較明顯。效果上,因為系統開銷,投入的資源跟性能提升并不是線性的,比如增加 4 個 worker,性能則可能提升 2 倍左右,而不是 4 倍。通過 TPCH 的測試效果,表明在 Ad-Hoc 查詢場景,普遍都有加速效果。
并行查詢功能說明
現在支持的并行場景主要是以下 3 種:
parallel sequential scan
parallel join
parallel aggregation
鑒于安全考慮,以下 4 種場景不支持并行:
公共表表達式(CTE)的掃描
臨時表的掃描
外部表的掃描(除非外部數據包裝器有一個 IsForeignScanParallelSafeAPI)
對 InitPlan 或 SubPlan 的訪問
使用并行查詢,還有以下限制:
必須保證是嚴格的 read only 模式,不能改變 database 的狀態
查詢執行過程中,不能被掛起
隔離級別不能是 SERIALIZABLE
不能調用 PARALLEL UNSAFE 函數
并行查詢有基于代價策略的判斷,譬如小數據量時默認還是普通執行。在 PostgreSQL 的配置參數中,提供了一些跟并行查詢相關的參數。我們想測試并行,一般設置下面兩個參數:
force_parallel_mode:強制開啟并行模式的開關
max_parallel_workers_per_gather:設定用于并行查詢的 worker 進程數
一個簡單的兩表 Join 查詢場景,使用并行查詢模式的查詢計劃如下:


并行查詢開啟后,解析器會生成一份 Gather…Partial 風格的執行計劃,這意味著到 Executor 層,會將 Partial 部分的計劃并行執行。
執行計劃里可以看到,在做并行查詢時,額外創建了 2 個 worker 進程,加上原來的 master 進程,總共 3 個進程。Join 的驅動表數據被平均分配了 3 份,通過并行 scan 分散了 I / O 操作,之后跟大表數據分別做 Join。
并行查詢的實現
PostgreSQL 的并行由多個進程的機制完成。每個進程在內部稱之為 1 個 worker,這些 worker 可以動態地創建、銷毀。PostgreSQL 在 SQL 語句解析和生成查詢計劃階段并沒有并行。在執行器(Executor)模塊,由多個 worker 并發執行被分片過的子任務。即使在查詢計劃被并行執行的環節,一直存在的進程也會充當一個 worker 來完成并行的子任務,我們可以稱之為主進程。同時,根據配置參數指定的 worker 數,再啟動 n 個 worker 進程來執行其他子計劃。
PostgreSQL 內延續了共享內存的機制,在每個 worker 初始化時就為每個 worker 分配共享內存,用于 worker 各自獲取計劃數據和緩存中間結果。這些 worker 間沒有復雜的通信機制,而是都由主進程做簡單的通信,來啟動和執行計劃。
PostgreSQL 中并行的執行模型如圖 1 所示。
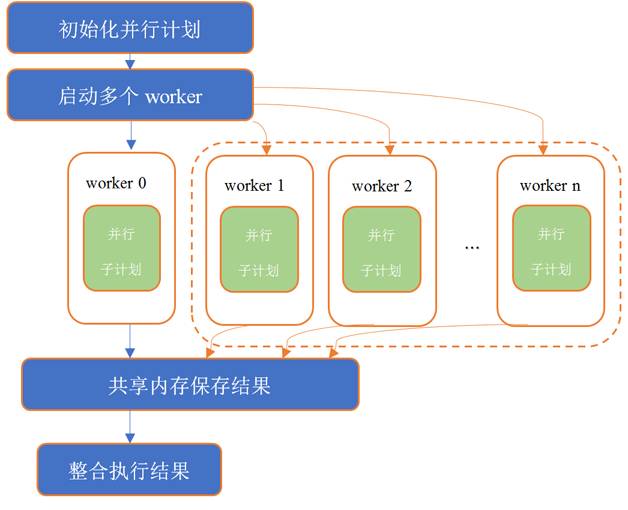
圖 1 PostgreSQL 并行查詢的框架
以上文的 Hash Join 的場景為例,在執行器層面,并行查詢的執行流程如圖 2 所示。
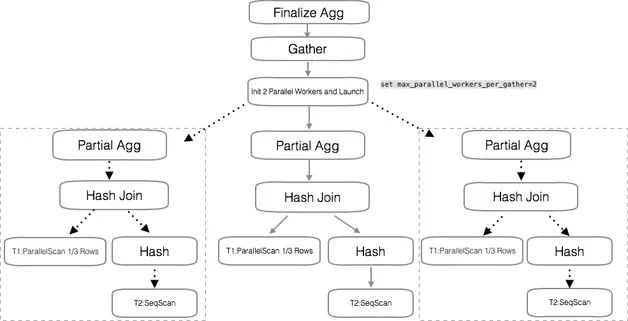
圖 2 并行查詢的執行流程
各 worker 按照以下方式協同完成執行任務:
首先,每個 worker 節點做的任務相同。因為是 Hash Join,worker 節點使用一個數據量小的表作為驅動表,做 Hash 表。每個 worker 節點都會維護這樣一個 Hash 表,而大表被平均分之后跟 Hash 表做數據 Join。
最底層的并行是磁盤的并行 scan,worker 進程可以從磁盤 block 里獲取自己要 scan 的 block。
Hash Join 后的數據是全部數據的子集。對于 count() 這種聚合函數,數據子集上可以分別做計算,最后再合并,結果上可以保證正確。
數據整合后,做一次總的聚合操作。
worker 進程又是如何創建和運行的?首先來看 worker 的創建邏輯(參見圖 3)。
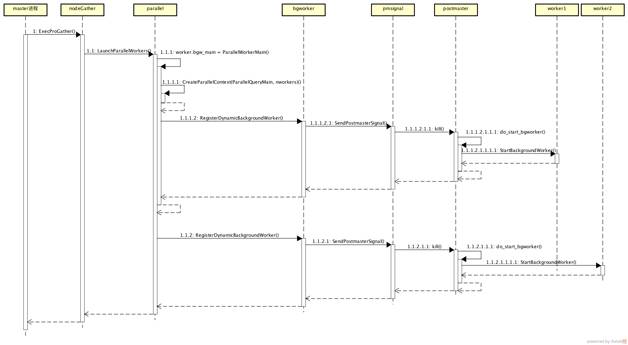
圖 3 PostgreSQL 的 worker 創建
PostgreSQL 的并行處理,以 worker 動態創建為前提。worker 可以由主進程初始化出來,并且在上下文中,先指定好入口函數。
并行查詢中,入口函數被指定為 ParallelWorkerMain。而 ParallelWorkerMain 函數里,在完成一系列信號代理設定后,會調用 ParallelQueryMain 來執行查詢。ParallelQueryMain 創建了一個新的執行器上下文,遞歸執行并行子查詢計劃。
用來并行查詢的 worker 進程接收主進程的信號,比如一旦發送創建進程的信號,worker 進程就會啟動,緊接著執行 ParallelWorkerMain 函數。進而,ParallelQueryMain 也會執行,各個 worker 進程獨立執行子計劃,執行結果會存在共享內存里。所有進程執行結束后,master 進程會去搜集共享內存里的結果數據(tuple),做數據整合。
并行查詢的改進
并行查詢的特性公布后,不乏對并行的評價和之后的改進計劃。社區并行查詢的開發者在博客中提到準備做一個大的共享 Hash Table,這樣 Hash Join 操作的并行度會進一步提升。
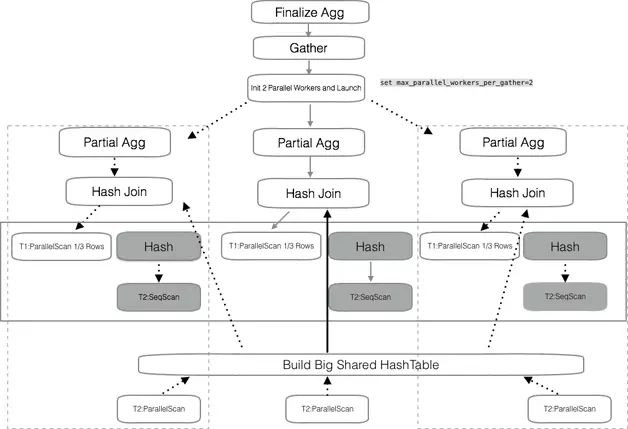
圖 4 創建大的 Hash 表共享數據
另外,對 PostgreSQL 而言,反倒是基于其 folk 出來的一些數據庫產品先于它做了并行查詢的特性,可以學習參考:
Postgres-XC 的分布式框架
GreenPlum 的 MPP 架構
CitusDB 的分布式
VitesseDB 基于多線程的并行
Fujitsu 的 Fujitsu Enterprise PostgreSQL 的并行
其中開源數據庫 GreenPlum 并行架構很有借鑒意義。GreenPlum 的并行查詢設計了一個專門的調度器來協調查詢任務的分配,而 PostgreSQL 沒有這樣的設計。關于 GreenPlum 的執行框架,簡單講是以下三層結構:
調度器(QD):調度器發送優化后的查詢計劃給所有數據節點(Segments)上的執行器(QE)。調度器負責任務的執行,包括執行器的創建、銷毀、錯誤處理、任務取消、狀態更新等。
執行器(QE):執行器收到調度器發送的查詢計劃后,開始執行自己負責的那部分計劃。典型的操作包括數據掃描、哈希關聯、排序、聚集等。
Interconnect:負責集群中各個節點間的數據傳輸
GreenPlum 會根據數據分布情況做數據的廣播和重分布,這是 PostgreSQL 的并行模型可以借鑒的。
僅僅是一個大的 Hash Table,在數據訪問上有串行的開銷,worker 的并行仍然受限。如圖 5 所示,大表和小表 Join 的場景參考 GreenPlum 的數據廣播機制,驅動表的數據可以給每個 worker 進程準備一個拷貝,相當于廣播了一份數據。這樣數據被高度共享,并行的效果會更好。
除了 PostgreSQL 生態的數據庫,關系型數據庫老大哥 Oracle 在并行查詢上已經積累了 30 年的經驗,也需要借鑒。在 Oracle 的官方手冊中,有對其并行查詢機制做出的說明。
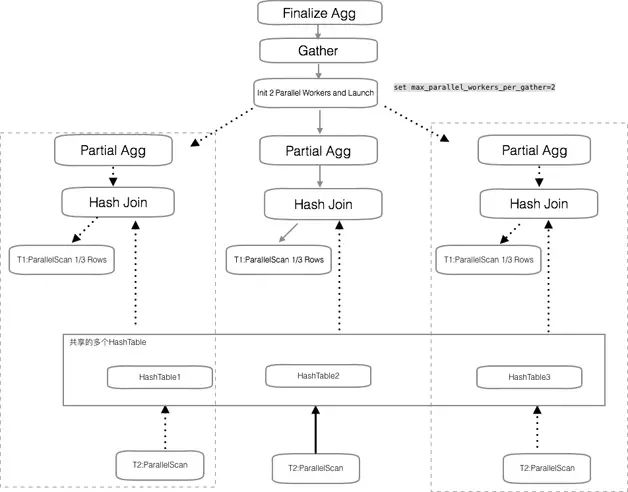
圖 5 借鑒 GreenPlum 的廣播機制提升并行效果
Oracle 在每個操作環節,都能把數據高度分片,可以參考圖 6 所示的 Hash Join 的并行。
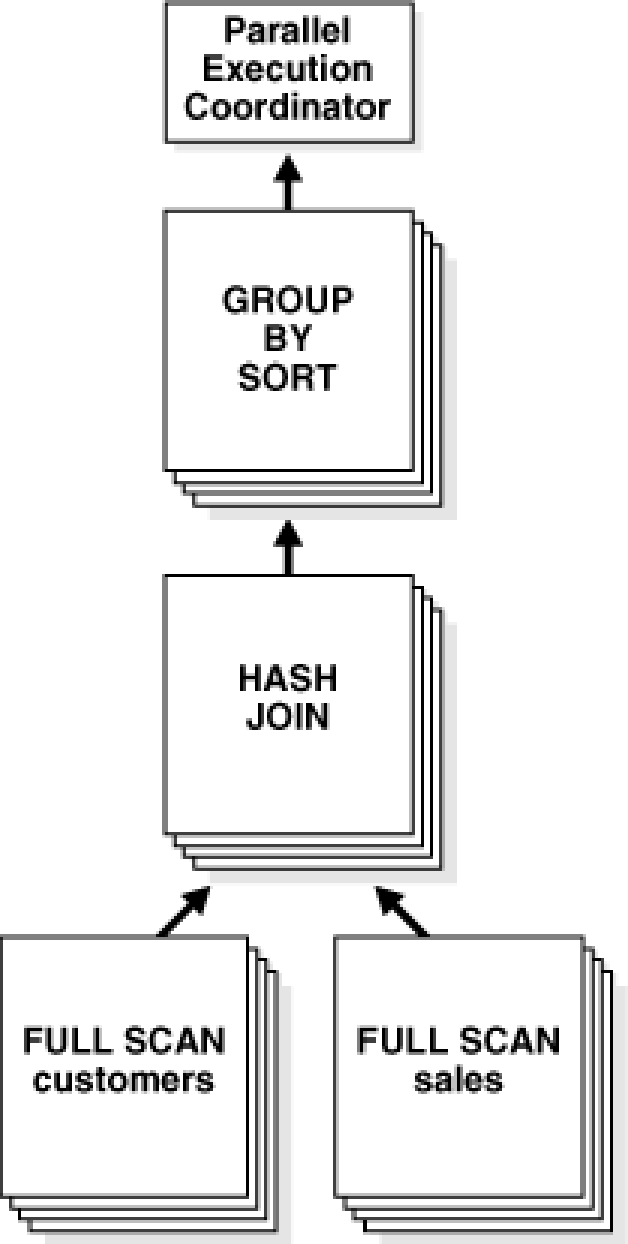
圖 6 Oracle 的 Hash Join 操作的并行流程
而在內部并行控制上,數據被分組后,不管是 scan 還是排序,幾組 worker 對分組的數據都能分治。
也就是說 Oracle 做到了操作符(Operator)Level 的并行。在每個操作中,把數據分片后動態的并行運算。可以看到 Oracle 的并行查詢在做 Operator 級別的并行,每個操作環節,都能把數據分片后分而治之,并行程度非常高。這對數據的流轉要求也很高,數據和操作既能水平分治也能垂直分治。
PostgreSQL 目前是任務級別的并行,將原先的執行計劃垂直拆分成幾個可以分離的子任務,并行實現簡單,但在大數據量時并行度不夠,而且共享內存的訪問負荷加重,性能提升不明顯。
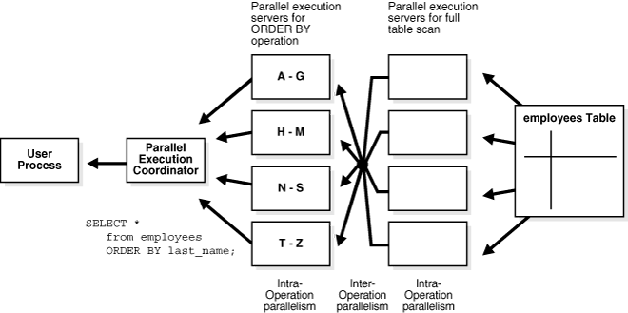
圖 7 Oracle 內部動態的并行操作
參考 Oracle 的方式,按上圖改進后,worker 不再是單獨執行 1 個任務,而是隨時被調用執行操作。數據根據操作分層、分片、廣播,worker 進程為數據操作服務,而不是數據為 worker 服務。這樣在超大規模數據的場景,驅動表作為 producer 做數據 partition,外表作為 consumer 做 operator 運算。多組這樣的操作產生的并行計算更自由,性能也更有想象空間,也是我們團隊目前在嘗試的方向。
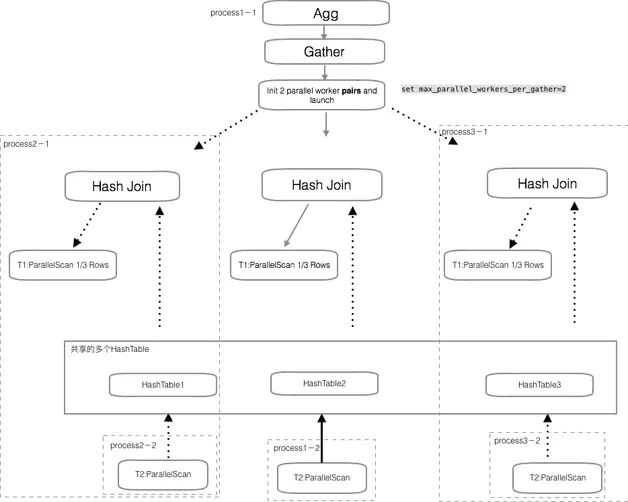
圖 8 通過數據分組和 worker 分組提升 PostgreSQL 的并行
看完了這篇文章,相信你對“PostgreSQL 如何實現并行查詢”有了一定的了解,如果想了解更多相關知識,歡迎關注丸趣 TV 行業資訊頻道,感謝各位的閱讀!











