共計 4311 個字符,預計需要花費 11 分鐘才能閱讀完成。
如何理解 Kubernetes 中 Pod 間共享內存,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
一些公共服務組件在追求性能過程中,與業務耦合太緊,造成在制作基礎鏡像時,都會把這些基礎組件都打包進去,因此當業務鏡像啟動后,容器里面一大堆進程,這讓 Kubernetes 對 Pod 的管理存在很大隱患。為了讓業務容器瘦身,更是為了基礎組件自身的管理更獨立和方便,將基礎組件從業務鏡像中剝離并 DaemonSet 容器化部署。然而一些基礎組件 Agent 與業務 Pod 之間通過共享內存的方式進行通信,同一 Node 中跨 Pod 的共享內存方案是首先要解決的問題。
一、為什么要將公共基礎組件 Agent 進行 DaemonSet 部署
自研的公共基礎組件,比如服務路由組件、安全組件等,通常以進程方式部署在 Node 上并同時為 Node 上所有的業務提供服務,微服務及容器化之后,服務數量成百上千的增長,如果以 sidecar 或者打包到業務 Image 中繼續 Per Pod Per Agent 的方式部署, 那么基礎組件的 Server 端的壓力可能也會成百上千的增長,風險是很大的。因此,我們希望能以 DaemonSet 方式部署這些組件的 Agents。
先說說 Kubernetes 大行其道的今天,如果不將這些基礎組件從業務 Pod 中剝離,存在哪些問題:
業務容器中存在一大堆進程,我們在為 Pod 申請資源 (cpu/mem request and limit) 時,不僅要考慮業務應用本身的資源消耗,還要考慮這些基礎組件的資源消耗。而且一旦某些 Agent 有 Bug,比如內存泄漏,這將導致 Pod 牽連被重建,甚至 Cgroup OOM 在 kill 進程時,可能將業務進程 kill 了。
違背了 Kubernetes 微服務的部署最佳實踐:Per Process Per Contaienr,并且業務進程在前臺運行,使其與容器共生死,不然這將導致 Kubernetes 無法根據業務進程狀態關聯到容器狀態,進而進行高可用管理。
一個 Node 上運行 10 個 Pod,那么就會有 x10 的基礎組件數量在 Node 上。沒有容器化之前,一個 Node 只要部署一個組件進程即可,容器化之后,集群中組件 Agents 數量要幾十倍的增長, 如果業務進行了微服務拆分,這個指數會更大,這些基礎組件服務端是否能承受比以往高幾十倍上百倍的通信請求,這是未知的。
如果你要全網升級某個基礎組件 Agent,那你可能會瘋掉,你需要重新打所有業務鏡像,然后全網業務要進行灰度升級。因為一個 Agent 的升級,導致你不得不重建業務 Pod。你可能會說,基礎組件 Agents 都會有自己的熱升級方案,我們通過它們的方案升級就好了呀,那你將引入很大麻煩:Agents 的熱升級因為無法被 Kubernetes 感知,將引發 Kubernetes 中集群中的數據不一致問題,那就真的要回到虛擬機或者物理機部署的玩法了。當然,這樣的需求,我們也想過通過 Operator 也實現,但代價太大了,而且很不 CloudNative!
將基礎組件 Agents 從業務 Pod 中剝離,以上的問題都能解決了,架構上的解耦帶來的好處無需多言。而且我們可以通過 Kubernetes 管理這些基礎組件 Agents 了,享受其自愈、滾動升級等好處。
二、Linux 共享內存機制
然而,理想很美好,現實很殘酷。首先要解決的問題是,有些組件 Agent 與業務 Pod 之間是通過共享內存通信的,這跟 Kubernetes 微服務的最佳實踐背道而馳。
大家都知道,Kubernetes 單個 Pod 內是共享 IPC 的,并且可以通過掛載 Medium 為 Memory 的 EmptyDir Volume 共享同一塊內存 Volume。
首先我們來了解一下 Linux 共享內存的兩種機制:
POSIX 共享內存(shm_open()、shm_unlink())
System V 共享內存(shmget()、shmat()、shmdt())
其中,System V 共享內存歷史悠久,一般的 UNIX 系統上都有這套機制;而 POSIX 共享內存機制接口更加方便易用,一般是結合內存映射 mmap 使用。
mmap 和 System V 共享內存的主要區別在于:
sysv shm 是持久化的,除非被一個進程明確的刪除,否則它始終存在于內存里,直到系統關機
mmap 映射的內存在不是持久化的,如果進程關閉,映射隨即失效,除非事先已經映射到了一個文件上
/dev/shm 是 Linux 下 sysv 共享內存的默認掛載點
POSIX 共享內存是基于 tmpfs 來實現的。實際上,更進一步,不僅 PSM(POSIX shared memory),而且 SSM(System V shared memory)在內核也是基于 tmpfs 實現的。
從這里可以看到 tmpfs 主要有兩個作用:
用于 SYSV 共享內存,還有匿名內存映射;這部分由內核管理,用戶不可見
用于 POSIX 共享內存,由用戶負責 mount,而且一般 mount 到 /dev/shm;依賴于 CONFIG_TMPFS
雖然 System V 與 POSIX 共享內存都是通過 tmpfs 實現,但是受的限制卻不相同。也就是說 /proc/sys/kernel/shmmax 只會影響 SYS V 共享內存,/dev/shm 只會影響 Posix 共享內存。實際上,System V 與 Posix 共享內存本來就是使用的兩個不同的 tmpfs 實例(instance)。
SYS V 共享內存能夠使用的內存空間只受 /proc/sys/kernel/shmmax 限制;而用戶通過掛載的 /dev/shm,默認為物理內存的 1 /2。
概括一下:
POSIX 共享內存與 SYS V 共享內存在內核都是通過 tmpfs 實現,但對應兩個不同的 tmpfs 實例,相互獨立。
通過 /proc/sys/kernel/shmmax 可以限制 SYS V 共享內存的最大值,通過 /dev/shm 可以限制 POSIX 共享內存的最大值(所有之和)。
三、同一 Node 上夸 Pod 的共享內存方案
基礎組件 Agents DaemonSet 部署后,Agents 和業務 Pod 分別在同一個 Node 上不同的 Pod,那么 Kubernetes 該如何支持這兩種類型的共享內存機制呢?
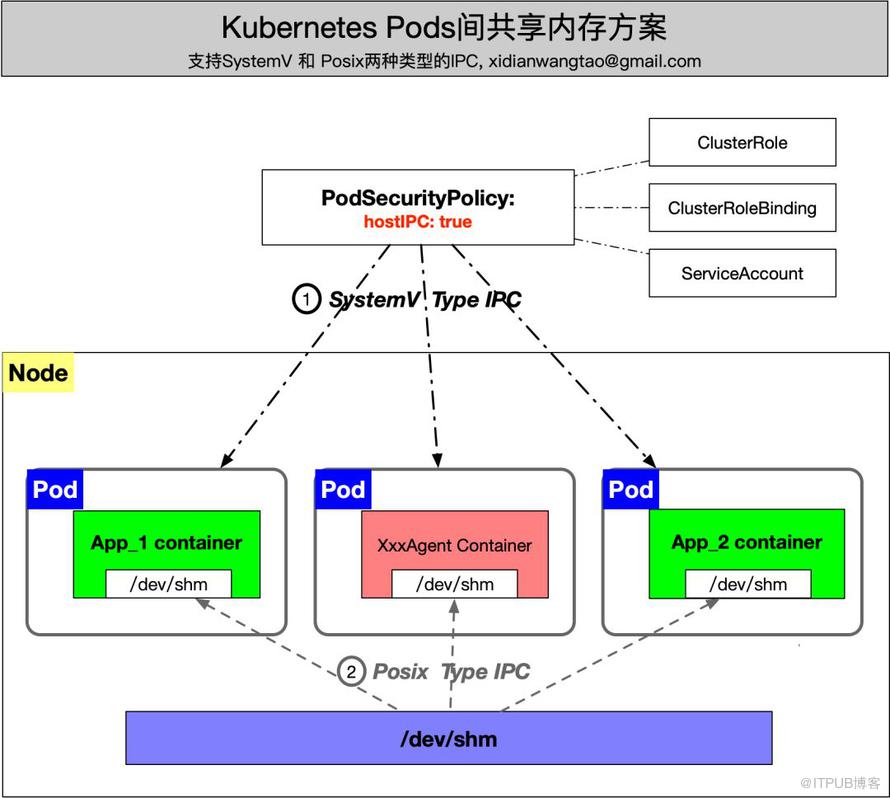
當然,安全性上做出了犧牲,但在非容器化之前 IPC 的隔離也是沒有的,所以這一點是可以接受的。
四、灰度上線
對于集群中的存量業務,之前都是將 Agents 與業務打包在同一個 docker image,因此需要有灰度上線方案,以保證存量業務不受影響。
首先創建好對應的 Kubernetes ClusterRole, SA, ClusterRoleBinding, PSP Object。關于 PSP 的內容,請參考官方文檔介紹 pod-security-policy。
在集群中任意選擇部分 Node,給 Node 打上 Label(AgentsDaemonSet:YES)和 Taint(AgentsDaemonSet=YES:NoSchedule)。
$ kubectl label node $nodeName AgentsDaemonSet=YES
$ kubectl taint node $nodeName AgentsDaemonSet=YES:NoSchedule(安卓系統可左右滑動查看全部代碼)
部署 Agent 對應的 DaemonSet(注意 DaemonSet 需要加上對應的 NodeSelector 和 Toleration, Critical Pod Annotations), Sample as follows:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: demo-agent
namespace: kube-system
labels:
k8s-app: demo-agent
spec:
selector:
matchLabels:
name: demo-agent
template:
metadata:
annotations:
scheduler.alpha.kubernetes.io/critical-pod:
labels:
name: demo-agent
spec:
tolerations:
- key: AgentsDaemonSet
operator: Equal
value: YES
effect: NoSchedule
hostNetwork: true
hostIPC: true
nodeSelector:
AgentsDaemonSet: YES
containers:
- name: demo-agent
image: demo_agent:1.0
volumeMounts:
- mountPath: /dev/shm
name: shm
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumes:
- name: shm
hostPath:
path: /dev/shm
type: Directory在該 Node 上部署不包含基礎組件 Agent 的業務 Pod,檢查所有基礎組件和業務是否正常工作,如果正常,再分批次選擇剩余 Nodes,加上 Label(AgentsDaemonSet:YES)和 Taint(AgentsDaemonSet=YES:NoSchedule),DaemonSet Controller 會自動在這些 Nodes 創建這些 DaemonSet Agents Pod。如此逐批次完成集群中基礎組件 Agents 的灰度上線。
在高并發業務下,尤其還是以 C /C++ 代碼實現的基礎組件,經常會使用共享內存通信機制來追求高性能,丸趣 TV 小編給出了 Kubernetes Pod 間 Posix/SystemV 共享內存方式的折中方案,以犧牲一定的安全性為代價,請知悉。當然,如果微服務 / 容器化改造后,基礎服務的 Server 端確定不會有壓力,那么建議以 SideCar Container 方式將基礎服務的 Agents 與業務 Container 部署在同一 Pod 中,利用 Pod 的共享 IPC 特性及 Memory Medium EmptyDir Volume 方式共享內存。
關于如何理解 Kubernetes 中 Pod 間共享內存問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注丸趣 TV 行業資訊頻道了解更多相關知識。











