共計 3071 個字符,預計需要花費 8 分鐘才能閱讀完成。
本篇內容介紹了“KubeVela+KEDA 有什么作用”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓丸趣 TV 小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
伸縮 Kubernetes
當管理 Kubernetes 集群和應用程序時,你需要仔細監視各種事情,比如:
集群容量——我們是否有足夠的可用資源來運行我們的工作負載?
應用程序工作負載——應用程序有足夠的可用資源嗎?它能跟上待完成的工作嗎?(像隊列深度)
為了實現自動化,你通常會設置警報以獲得通知,甚至使用自動伸縮。Kubernetes 是一個很好的平臺,它可以幫助你實現這個即時可用的功能。 通過使用 Cluster Autoscaler 組件可以輕松地伸縮集群,該組件將監視集群,以發現由于資源短缺而無法調度的 pod,并開始相應地添加 / 刪除節點。 因為 Cluster Autoscaler 只在 pod 調度過度時才會啟動,所以你可能會有一段時間間隔,在此期間你的工作負載沒有啟動和運行。 Virtual Kubelet(一個 CNCF 沙箱項目)是一個巨大的幫助,它允許你向 Kubernetes 集群添加一個“虛擬節點”,pod 可以在其上調度。 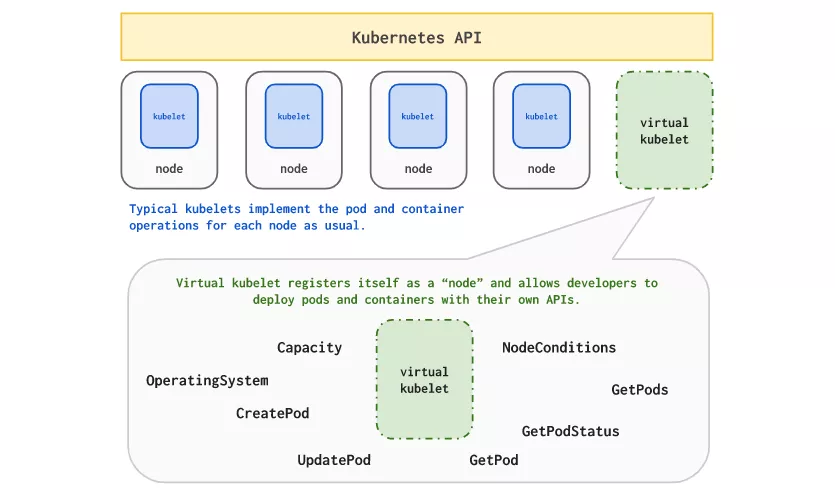
通過這樣做,平臺供應商(如阿里巴巴、Azure、HashiCorp 和其他)允許你將掛起的 pod 溢出到集群之外,直到它提供所需的集群容量來緩解這個問題。 除了伸縮集群,Kubernetes 還允許你輕松地伸縮應用程序:
Horizontal Pod Autoscaler(HPA)允許你添加 / 刪除更多的 Pod 到你的工作負載中,以 scale in/out(添加或刪除副本)。
Vertical Pod Autoscaler(VPA)允許你添加 / 刪除資源到你的 Pod 以 scale up/down(添加或刪除 CPU 或內存)。
所有這些為你伸縮應用程序提供了一個很好的起點。
HPA 的局限性
雖然 HPA 是一個很好的起點,但它主要關注 pod 本身的指標,允許你基于 CPU 和內存伸縮它。也就是說,你可以完全配置它應該如何自動縮放,這使它強大。 雖然這對于某些工作負載來說是理想的,但你通常想要基于其他地方如 Prometheus、Kafka、云供應商或其他事件上的指標進行伸縮。 多虧了外部指標支持,用戶可以安裝指標適配器,從外部服務中提供各種指標,并通過使用指標服務器對它們進行自動伸縮。 但是,有一點需要注意,你只能在集群中運行一個指標服務器,這意味著你必須選擇自定義指標的來源。 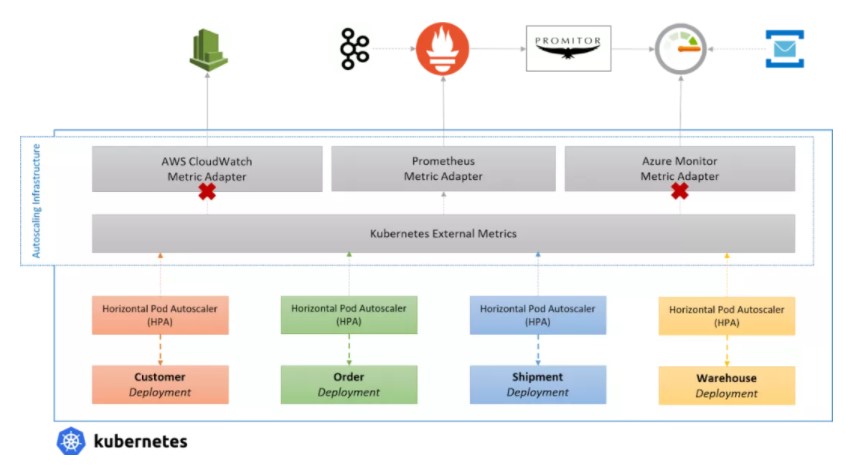
你可以使用 Prometheus 和工具,比如 Promitor,從其他提供商那里獲取你的指標,并將其作為單一的真相來源來進行伸縮,但這需要大量的管道(plumbing)和工作來進行擴展。 肯定有更簡單的方法……是的,使用 Kubernetes Event-Driven Autoscaling(KEDA)!
KEDA 是什么?
Kubernetes Event-Driven Autoscaling(KEDA)是一個用于 Kubernetes 的單用途事件驅動自動伸縮器,可以很容易地將其添加到 Kubernetes 集群中以伸縮應用程序。 它的目標是使應用程序自動擴展非常簡單,并通過支持伸縮到零(scale-to-zero)來優化成本。 KEDA 去掉了所有的伸縮基礎設施,并為你管理一切,允許你在 30 多個系統上進行伸縮或使用自己的伸縮器進行擴展。 用戶只需要創建 ScaledObject 或 ScaledJob 來定義你想要伸縮的對象和你想要使用的觸發器;KEDA 會處理剩下的一切! 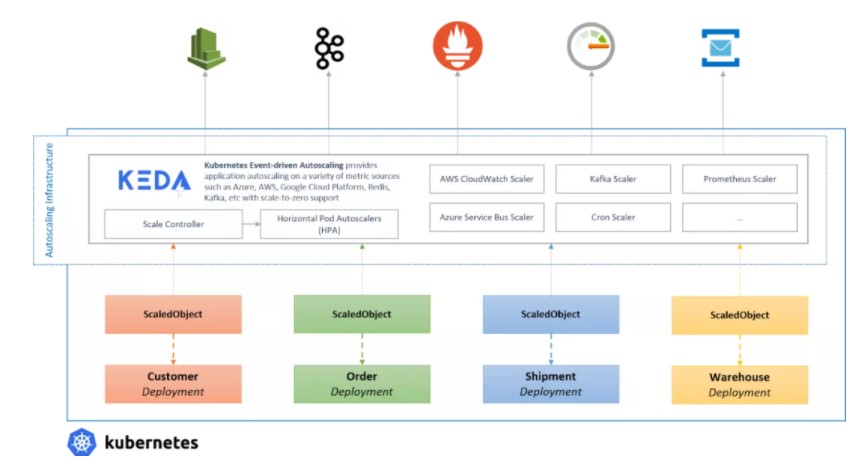
你可以伸縮任何東西;即使它是你正在使用的另一個工具的 CRD,只要它實現 /scale 子資源。 那么,KEDA 重新發明輪子了嗎?不!相反,它通過在底層使用 HPA 來擴展 Kubernetes,HPA 使用我們的外部指標,這些指標由我們自己的指標適配器提供,該適配器取代了所有其他適配器。 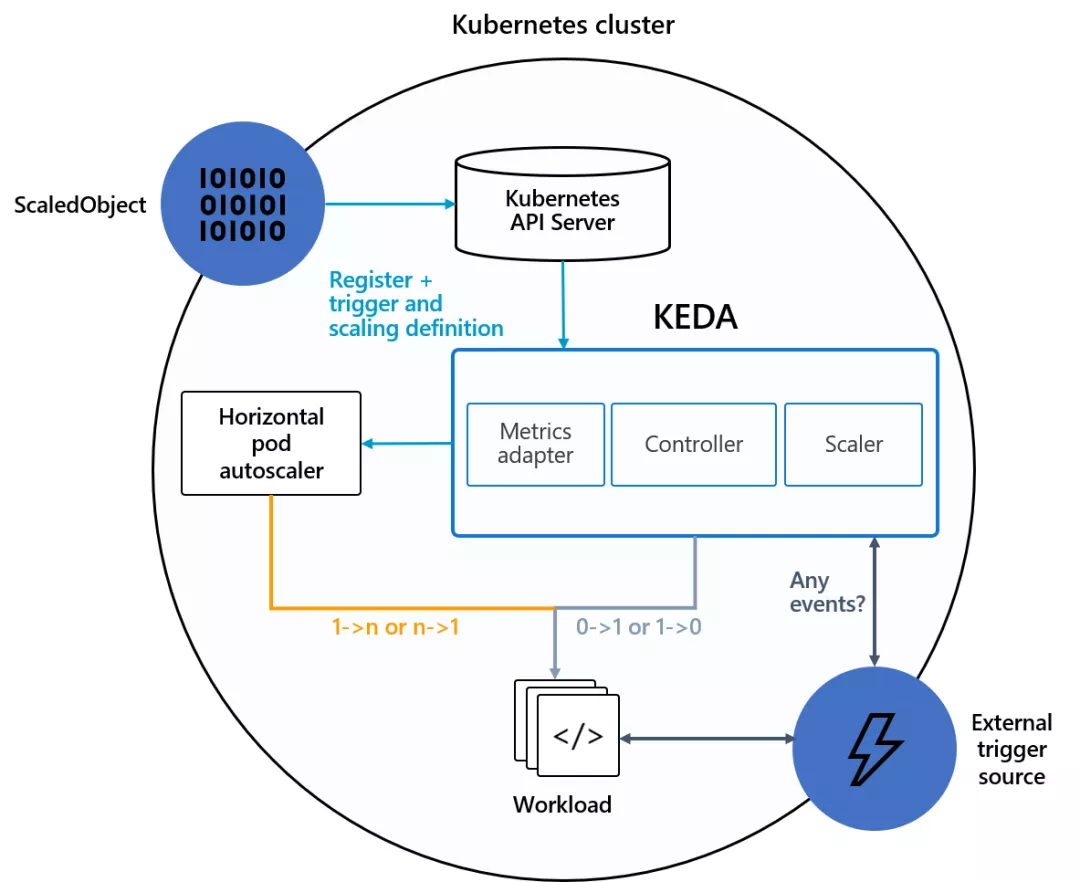
去年,KEDA 加入了 CNCF,作為 CNCF 沙箱項目,計劃今年晚些時候提案升級到孵化階段。
阿里巴巴基于 OAM/KubeVela 和 KEDA 的實踐
企業分布式應用服務(EDAS)作為阿里云上的主要企業 PaaS 產品,多年來以巨大的規模服務于公有云上的無數開發者。從架構的角度來看,EDAS 是與 KubeVela 項目一起構建的。其總體架構如下圖所示。 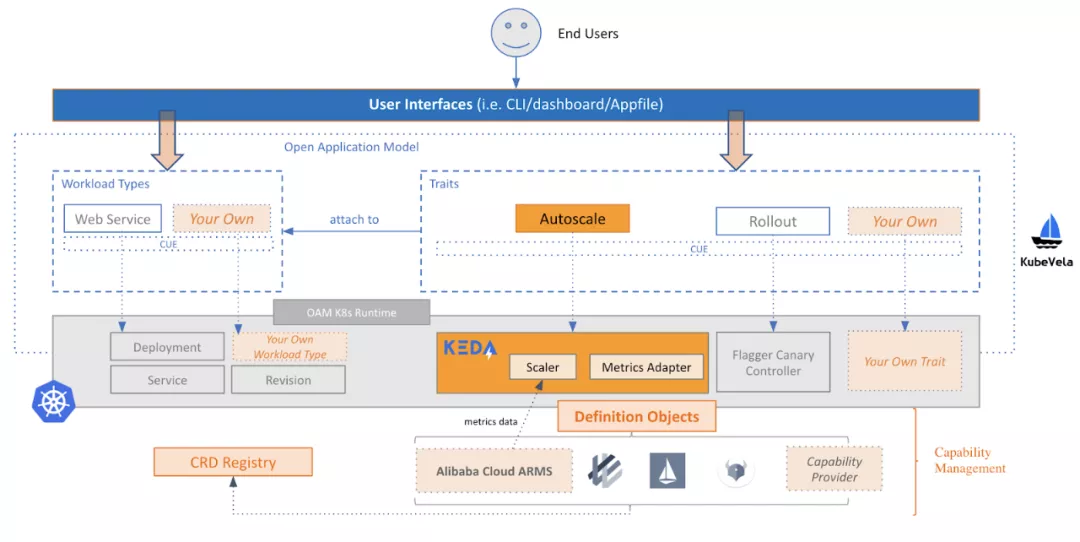
在生產上,EDAS 在阿里云上集成了 ARMS 監控服務,提供監控和應用的細粒度指標。EDAS 團隊在 KEDA 項目中添加了一個 ARMS Scaler 來執行自動縮放。他們還添加了一些特性,并修復了 KEDA v1 版本中的一些 bug。包括:
當有多個觸發器時,這些值將被求和,而不是作為單獨的值留下。
當創建 KEDA HPA 時,名稱的長度將被限制為 63 個字符,以避免觸發 DNS 投訴。
不能禁用觸發器,這可能會在生產中引起麻煩。
EDAS 團隊正在積極地將這些修復程序發送給上游 KEDA,盡管其中一些已經添加到 V2 版本中。
為什么阿里云將 KEDA 標準化為其應用的自動伸縮器
當涉及到自動擴展特性時,EDAS 最初使用上游 Kubernetes HPA 的 CPU 和內存作為兩個指標。然而,隨著用戶群的增長和需求的多樣化,EDAS 團隊很快發現了上游 HPA 的局限性:
對定制指標的支持有限,特別是對應用程序級細粒度指標的支持。上游 HPA 主要關注容器級指標,比如 CPU 和內存,這些指標對于應用程序來說太粗糙了。反映應用程序負載的指標(如 RT 和 QPS)不受現成支持。是的,HPA 可以擴展。然而,當涉及到應用程序級指標時,這種能力是有限的。EDAS 團隊在嘗試引入細粒度的應用程序級指標時,經常被迫分叉代碼。
不支持伸縮到零。當他們的微服務沒有被使用時,許多用戶都有將規模伸縮到零的需求。這一需求不僅限于 FaaS/ 無服務器工作負載。它為所有用戶節省成本和資源。目前,上游 HPA 不支持此功能。
不支持預定的伸縮。EDAS 用戶的另一個強烈需求是預定的伸縮能力。同樣,上游 HPA 不提供此功能,EDAS 團隊需要尋找非供應商鎖定的替代方案。
基于這些需求,EDAS 團隊開始規劃 EDAS 自動伸縮特性的新版本。與此同時,EDAS 在 2020 年初引入了 OAM,對其底層核心組件進行了徹底改革。OAM 為 EDAS 提供了標準化的、可插入的應用程序定義,以取代其內部的 Kubernetes 應用程序 CRD。該模型的可擴展性使 EDAS 能夠輕松地與 Kubernetes 社區的任何新功能集成。在這種情況下,EDAS 團隊試圖將對 EDAS 新的自動伸縮特性的需求與 OAM 自動伸縮特性的標準實現相結合。 基于用例,EDAS 團隊總結了三個標準:
自動伸縮特性應該將自己呈現為一個簡單的原子功能,而不需要附加任何復雜的解決方案。
指標應該是可插入的,因此 EDAS 團隊可以對其進行定制,并在其之上構建以支持各種需求。
它需要開箱即用地支持伸縮到零。
經過詳細的評估,EDAS 團隊選擇了 KEDA 項目,該項目是由微軟和紅帽開源的,已捐贈給 CNCF。KEDA 默認提供了幾個有用的 Scaler,并開箱即用地支持伸縮到零。它為應用程序提供了細粒度的自動伸縮。它具有 Scalar 和 Metric 適配器的概念,支持強大的插件架構,同時提供統一的 API 層。最重要的是,KEDA 的設計只關注自動伸縮,這樣就可以輕松地將其集成為 OAM 特性。總的來說,KEDA 非常適合 EDAS。
“KubeVela+KEDA 有什么作用”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注丸趣 TV 網站,丸趣 TV 小編將為大家輸出更多高質量的實用文章!











