共計 4689 個字符,預計需要花費 12 分鐘才能閱讀完成。
如何進行 sysbench 的框架實現,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
sysbench 是一個非常經典的綜合性能測試工具,它支持 CPU,IO,內存,尤其是數據庫的性能測試。那它是怎么做到通用性的呢,總結一句話是大量運用了重載的方法。
sysbench 總體架構
sysbench 是一個總體框架,它用來操作各個測性能的計算,那各個部門只需要做的一件事情是聲明需要的實現。只要理解了這三個 struct 就可以了:
/* 某個測試用例的整體結構 */typedef struct sb_test
{ const char *sname; const char *lname; /* 下面有具體說明 */
sb_operations_t ops; sb_builtin_cmds_t builtin_cmds; sb_arg_t *args; sb_list_item_t listitem;
} sb_test_t;/* 某個測試用例的具體操作實現結構 */typedef struct{
sb_op_init *init; /* initialization function */
sb_op_prepare *prepare; /* called after timers start, but
before thread execution */
sb_op_thread_init *thread_init; /* thread initialization
(called when each thread starts) */
sb_op_print_mode *print_mode; /* print mode function */
sb_op_next_event *next_event; /* event generation function */
sb_op_execute_event *execute_event; /* event execution function */
sb_op_report *report_intermediate; /* intermediate reports handler */
sb_op_report *report_cumulative; /* cumulative reports handler */
sb_op_thread_run *thread_run; /* main thread loop */
sb_op_thread_done *thread_done; /* thread finalize function */
sb_op_cleanup *cleanup; /* called after exit from thread,
but before timers stop */
sb_op_done *done; /* finalize function */} sb_operations_t;/* 某個測試用例的三階段實現結構 */typedef struct{ sb_builtin_cmd_func_t *help; /* print help */
sb_builtin_cmd_func_t *prepare; /* prepare for the test */
sb_builtin_cmd_func_t *run; /* run the test */
sb_builtin_cmd_func_t *cleanup; /* cleanup the test database, files, etc. */} sb_builtin_cmds_t;拿最簡單的 CPU 性能計算舉例,它需要實現的是:
static sb_test_t cpu_test =
.sname = cpu , /*case 簡稱 */
.lname = CPU performance test ,/*case 全稱 */
.ops = {
.init = cpu_init, /* 初始化 case */
.print_mode = cpu_print_mode, /* case 啟動前,做說明 */
.next_event = cpu_next_event, /* 拿到下一個 event 的數據 */
.execute_event = cpu_execute_event, /* 具體執行這個 event */
.report_cumulative = cpu_report_cumulative, /* 階段性報告輸出 */
.done = cpu_done /* case 結束后,處理干凈 */
},
.args = cpu_args /* 子 case 需要的參數說明 */}; 看到這個后,把一個 case 需要做的事情描述很清楚了,從需要什么參數,到初始化,逐個 event 執行,函數定義很清晰。sysbench 的其他 case 也都這樣需要一個完整的結構說明,如 io 操作,則需要多一個 case 的 prepare 和 cleandown 聲明。
那 sysbench 的完整流程是怎樣呢?黃色部分是測試用例需要實現的。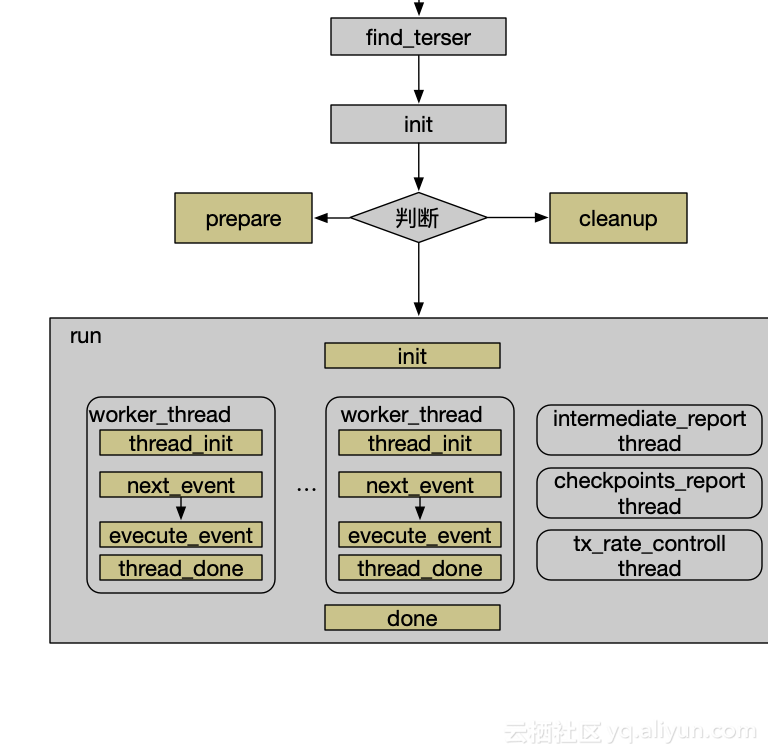
至此,可以清晰地看到 sysbench 的框架還是非常好理解。
上面 struct 里面有個 event 概念,不同的測試 event 的定義都不一樣:比如 CPU 的測試 case,一個 event 是完成求得小于某數(默認 10000)的所有質數。比如 fileio 的測試 case,一次 read 或者一次 write 操作就是一個 event。
sysbench 的線程介紹
worker_thread 具體實現是怎樣呢:欣賞下 sysbench.c 里面某子線程是如何執行的,代碼非常清晰易懂:
static int thread_run(sb_test_t *test, int thread_id){ sb_event_t event; int rc = 0; while (sb_more_events(thread_id) rc == 0)
{ event = test- ops.next_event(thread_id); if (event.type == SB_REQ_TYPE_NULL) break;
sb_event_start(thread_id);
rc = test- ops.execute_event(event, thread_id);
sb_event_stop(thread_id);
} return rc;
}
intermediate_report 線程:周期性輸出性能數據,參數項為:–report-interval=N, 對 CPU 的測試用例舉例:sysbench cpu –report-interval=1, 截取部分輸出結果如下:
Threads started![ 1s ] thds: 1 eps: 922.10 lat (ms,95%): 1.08[ 2s ] thds: 1 eps: 925.19 lat (ms,95%): 1.08[ 3s ] thds: 1 eps: 926.00 lat (ms,95%): 1.08[ 4s ] thds: 1 eps: 926.00 lat (ms,95%): 1.08[ 5s ] thds: 1 eps: 926.00 lat (ms,95%): 1.08[ 6s ] thds: 1 eps: 926.00 lat (ms,95%): 1.08[ 7s ] thds: 1 eps: 925.00 lat (ms,95%): 1.08[ 8s ] thds: 1 eps: 926.02 lat (ms,95%): 1.08[ 9s ] thds: 1 eps: 925.99 lat (ms,95%): 1.08[ 10s ] thds: 1 eps: 924.98 lat (ms,95%): 1.08每一秒輸出一個結果,eps 是每一秒的 event 數,lat 單位是毫秒,95 分位延遲數據是 1.08
checkpoints_report 線程:如果嫌周期性輸出不夠多,那么可以在某幾個時間點整體輸出,參數項為:
–report-checkpoints=[LIST,…]
還是對 CPU 測試用例舉例:sysbench cpu –report-checkpoints=3,8 run, 截取部分輸出結果如下:
Threads started!
[ 3s ] Checkpoint report:
CPU speed:
events per second: 923.01General statistics:
total time: 3.0001s
total number of events: 2771Latency (ms):
min: 1.08
avg: 1.08
max: 1.22
95th percentile: 1.08
sum: 3000.88Threads fairness:
events (avg/stddev): 2773.0000/0.00
execution time (avg/stddev): 3.0009/0.00[ 8s ] Checkpoint report:
CPU speed:
events per second: 924.47General statistics:
total time: 8.0001s
total number of events: 4622Latency (ms):
min: 1.08
avg: 1.08
max: 1.16
95th percentile: 1.08
sum: 4998.04Threads fairness:
events (avg/stddev): 4621.0000/0.00
execution time (avg/stddev): 4.9980/0.00tx_rate_controll 線程,控制每秒輸出量的一個線程:參數項為:
–rate=N, 默認是不做控制的。
還是拿 CPU 測試用例舉例,控制每秒跑 10 個 event:sysbench cpu run –rate=10, 截取部分輸出結果如下:
Running the test with following options:
Number of threads: 1
Target transaction rate: 10/sec
Initializing random number generator from current time
Prime numbers limit: 10000
Initializing worker threads...
Threads started!
CPU speed:
events per second: 8.87 # 沒那么精準哈 輸出速率控制在哪里呢?眼尖的人馬上可以看到是在 sb_more_events 函數。那 sb_more_events 函數主要是做什么呢:
判斷是否超時,默認是 10 秒
判斷是否到達最大 event 數,如果設置了的話
就是速率控制。
綜上,大概介紹了 sysbench 框架的總體實現。
看完上述內容,你們掌握如何進行 sysbench 的框架實現的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注丸趣 TV 行業資訊頻道,感謝各位的閱讀!











