共計(jì) 3564 個(gè)字符,預(yù)計(jì)需要花費(fèi) 9 分鐘才能閱讀完成。
這篇文章給大家介紹 Tensorflow 中 CNN 入門的手寫數(shù)字識(shí)別是怎樣的,內(nèi)容非常詳細(xì),感興趣的小伙伴們可以參考借鑒,希望對大家能有所幫助。
深度學(xué)習(xí)最令人興奮的領(lǐng)域之一就是計(jì)算機(jī)視覺。通過卷積神經(jīng)網(wǎng)絡(luò),我們已經(jīng)能夠創(chuàng)建自動(dòng)駕駛汽車系統(tǒng)、面部檢測系統(tǒng)和自動(dòng)醫(yī)學(xué)圖像分析等等。我將向你展示卷積神經(jīng)網(wǎng)絡(luò)的基本原理以及如何自己創(chuàng)建一個(gè)對手寫數(shù)字進(jìn)行分類的系統(tǒng)。
卷積神經(jīng)網(wǎng)絡(luò)的功能似乎是人類大腦中生物功能的復(fù)制,早在 1959 年,David Hubel 和 Torsten Wiesel 對貓和猴進(jìn)行了研究,這些研究揭示了動(dòng)物視覺皮層的功能。他們發(fā)現(xiàn)的是,許多神經(jīng)元具有小的局部接受性,即僅對整個(gè)視野的一小塊有限區(qū)域起反應(yīng)。他們發(fā)現(xiàn)某些神經(jīng)元會(huì)對某些特定模式做出反應(yīng),例如水平線、垂直線和其他圓形。他們還發(fā)現(xiàn)其他神經(jīng)元具有更大的感受野并且被更復(fù)雜的模式刺激,這些模式是由較低水平神經(jīng)元收集的信息組合。這些發(fā)現(xiàn)奠定了我們現(xiàn)在稱之為卷積神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)。接下來,我們逐一介紹卷積神經(jīng)網(wǎng)絡(luò)的組成。
1、卷積層
卷積神經(jīng)網(wǎng)絡(luò)中每層卷積層由若干卷積單元組成,每個(gè)卷積單元的參數(shù)都是通過反向傳播算法最佳化得到的。卷積運(yùn)算的目的是提取輸入的不同特征,第一層卷積層可能只能提取一些低級(jí)的特征如邊緣、線條和角等層級(jí),更多層的網(wǎng)路能從低級(jí)特征中迭代提取更復(fù)雜的特征。你可以將每個(gè)過濾器描繪成一個(gè)窗口,該窗口在圖像的尺寸上滑動(dòng)并檢測屬性。濾鏡在圖像上滑動(dòng)的像素?cái)?shù)量稱為步幅。步幅為 1 意味著濾波器一次移動(dòng)一個(gè)像素,其中 2 的步幅將向前跳過 2 個(gè)像素。
在上面的例子中,我們可以看到一個(gè)垂直線檢測器。原始圖像為 6 ×6,它使用 3 ×3 濾鏡進(jìn)行掃描,步長為 1,從而產(chǎn)生 4 ×4 尺寸輸出。而過濾器僅對其視野左右列中的部分感興趣。通過對圖像的輸入求和并乘以 3×3 濾波器的配置,我們得到 3 +1+2-1-7-5=-7。然后濾波器向右移動(dòng)一步,然后計(jì)算 1 +0+3-2-3-1=-2。- 2 然后進(jìn)入 - 7 右側(cè)的位置。此過程將持續(xù)到 4 ×4 網(wǎng)格完成為止。之后,下一個(gè)特征圖將使用它自己的唯一過濾器 / 內(nèi)核矩陣計(jì)算自己的值。
2. 池化層
池化層的目標(biāo)是通過聚合卷積層收集的值或所謂的子采樣來進(jìn)一步降低維度。除了為模型提供一些正則化的方案以避免過度擬合之外,這還將減少計(jì)算量。它們遵循與卷積層相同的滑動(dòng)窗口思想,但不是計(jì)算所有值,而是選擇其輸入的最大值或平均值。這分別稱為最大池化和平均池化。
這兩個(gè)組件是卷積層的關(guān)鍵構(gòu)建塊。然后,你通常會(huì)重復(fù)此方法,進(jìn)一步減少特征圖的尺寸,但會(huì)增加其深度。每個(gè)特征圖將專門識(shí)別它自己獨(dú)特的形狀。在卷積結(jié)束時(shí),會(huì)放置一個(gè)完全連接的圖層,其具有激活功能,例如 Relu 或 Selu,用于將尺寸重新整形為適合的尺寸送入分類器。例如,如果你的最終轉(zhuǎn)換層為 3x3x128 矩陣,但你只預(yù)測 10 個(gè)不同的類,則需要將其重新整形為 1 ×1152 向量,并在輸入分類器之前逐漸減小其大小。完全連接的層也將學(xué)習(xí)它們自己的特征,如在典型的深度神經(jīng)網(wǎng)絡(luò)中。
現(xiàn)在讓我們看看在 MNIST 手寫數(shù)字?jǐn)?shù)據(jù)集上的 Tensorflow 中的實(shí)現(xiàn)。首先,我們將加載我們的庫。使用 sklearn 中的 fetch_mldata,我們加載 mnist 數(shù)據(jù)集并將圖像和標(biāo)簽分配給 x 和 y 變量。然后我們將創(chuàng)建我們的訓(xùn)練 / 測試裝置。最后,我們將舉幾個(gè)例子來了解任務(wù)。
接下來,我們將進(jìn)行一些數(shù)據(jù)增強(qiáng),這是提高模型性能的可靠方法。通過創(chuàng)建訓(xùn)練圖像的輕微變化,可以為模型創(chuàng)建正則化。我們將使用 Scipy 的 ndimage 模塊將圖像向右、向左、向上和向下移動(dòng) 1 個(gè)像素。這不僅提供了更多種類的例子,而且還會(huì)大大增加我們訓(xùn)練集的大小。
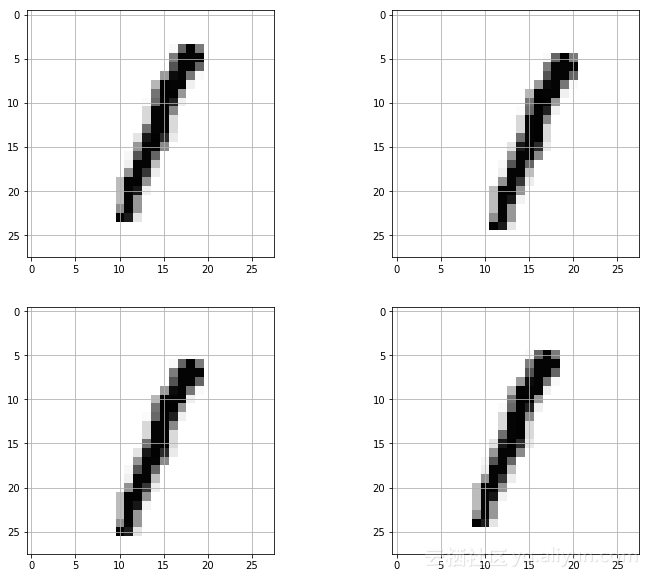
我將向你展示的最后一種數(shù)據(jù)增強(qiáng)的方式:使用 cv2 庫創(chuàng)建圖像的水平翻轉(zhuǎn)。我們還需要為這些翻轉(zhuǎn)圖像創(chuàng)建新標(biāo)簽,這與復(fù)制原始標(biāo)簽一樣簡單。
設(shè)置“flipCode = 0”將產(chǎn)生垂直翻轉(zhuǎn)
接下來,我們將創(chuàng)建一個(gè)輔助函數(shù),用于將隨機(jī)微型批次提供給我們的神經(jīng)網(wǎng)絡(luò)輸入。由于卷積層的性質(zhì),它們在前向和后向傳播步驟期間需要大量的存儲(chǔ)器。考慮具有 4 ×4 濾鏡的圖層,輸出 128 步幅為 1 的特征圖和具有尺寸 299×299 的 RGB 圖像輸入的 SAME 填充。參數(shù)的數(shù)量將相等(4x4x3+1)x128 = 6272. 現(xiàn)在考慮這 128 個(gè)特征圖中的每一個(gè)都計(jì)算 299×299 個(gè)神經(jīng)元,并且這些神經(jīng)元中的每一個(gè)都計(jì)算 4x4x3 輸入的加權(quán)和。這意味著我們需要 4x4x3x299x299x150=643,687,200 次計(jì)算,這只是一個(gè)訓(xùn)練的例子。
現(xiàn)在我們開始創(chuàng)建我們的網(wǎng)絡(luò)架構(gòu)。首先,我們?yōu)槲覀兊呐嘤?xùn)數(shù)據(jù) / 特征創(chuàng)建占位符。我們需要將它們重新整形為(-1,28,28,1)矩陣,因?yàn)?tensorflow conv2d 層需要 4 維輸入。我們將第一個(gè)維度設(shè)置為“null”,以允許將任意批量大小提供給占位符。
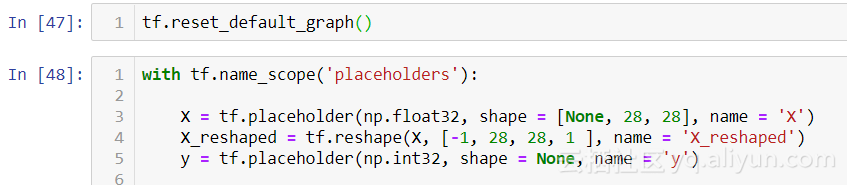
接著我們設(shè)計(jì)我們的卷積層,我是從 Le-NET5(由 Yann LeCun 開創(chuàng))網(wǎng)絡(luò)架構(gòu)中獲取靈感,該架構(gòu)因其在手寫數(shù)字分類方面成功而聞名。我建議你研究 Le-NET5 以及其他經(jīng)過驗(yàn)證的模型,這樣就可以了解哪種卷積網(wǎng)絡(luò)適用于不同的任務(wù)。鏈接:http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf。

我們模型卷積層的第一層由 12 個(gè)特征圖組成,使用 3 ×3 過濾器,步幅為 1。我們選擇了 SAME 填充,通過在輸入周圍添加一個(gè)零填充來保持圖像的尺寸。然后,我們設(shè)置最大池化層使用 3 ×3 過濾器,步幅為 1,這將輸出 13x13x12 矩陣。所以我們從一個(gè) 28x28x1 的圖像開始,然后我們將這個(gè)矩陣傳遞給第二個(gè)轉(zhuǎn)換層,第二個(gè)轉(zhuǎn)換層具有 3 ×3 過濾器的深度,stride= 1 和 SAME 填充。這將輸出一個(gè) 6 *6*16 維矩陣。你可以看到我們正在縮小特征圖的維度空間,但要更深入。接下來,我們使用 Selu 函數(shù)激活兩個(gè)密集層來減少每層輸入的數(shù)量大約一半,直到最終將它們輸入我們的 logits。

接著我們創(chuàng)建我們的損失函數(shù),在這種情況下,它將是 softmax 交叉熵,它將輸出多類概率。你可以將交叉熵視為各種數(shù)據(jù)點(diǎn)之間距離的度量。我們選擇 AdamOptimizer(自適應(yīng)矩估計(jì)),當(dāng)梯度下降時(shí)自動(dòng)調(diào)整它的學(xué)習(xí)率。最后,我們創(chuàng)建了一種評(píng)估結(jié)果的方法。Tensorflow 的 in_top_k 函數(shù)將計(jì)算我們的 logits 并選擇最高分。然后我們使用我們的準(zhǔn)確度變量輸出 0 -1%之間的百分比。
現(xiàn)在我們已經(jīng)為訓(xùn)練階段做好了準(zhǔn)備,讓我們看看我們的模型表現(xiàn)得如何。
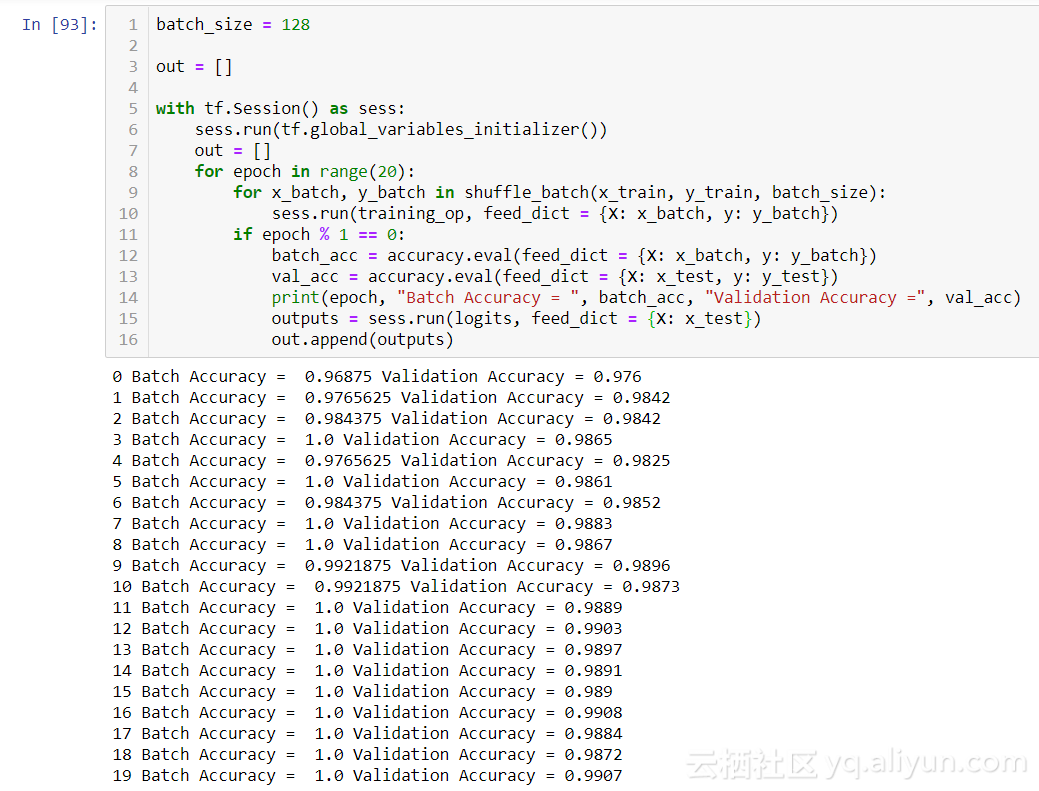
在第 19epoch,我們的正確率在 0.9907。這已經(jīng)比任何機(jī)器學(xué)習(xí)算法的結(jié)果更好,因此卷積已經(jīng)取得了領(lǐng)先。現(xiàn)在讓我們嘗試使用我們的移位功能 / 翻轉(zhuǎn)功能,并為我們的網(wǎng)絡(luò)添加兩個(gè)新元素:dropout 和批量標(biāo)準(zhǔn)化。
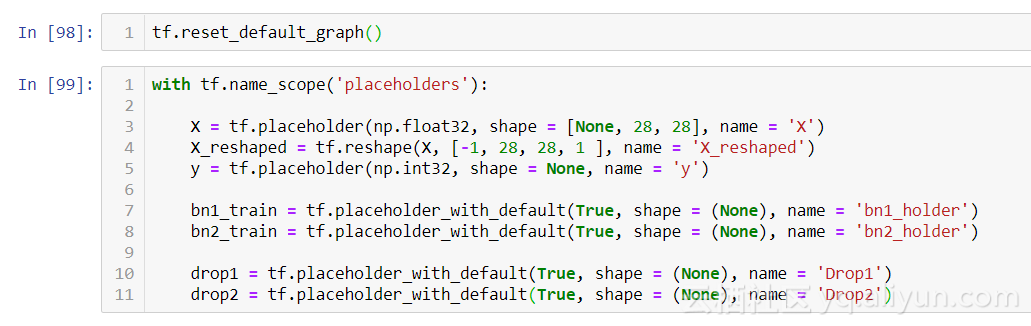
我們使用 placeholder_with_default 節(jié)點(diǎn)修改現(xiàn)有占位符,這些節(jié)點(diǎn)將保存批量標(biāo)準(zhǔn)化和 dropout 層生成的值。在訓(xùn)練期間,我們將這些值設(shè)置為 True,在測試期間,我們將通過設(shè)置為 False 將其關(guān)閉。
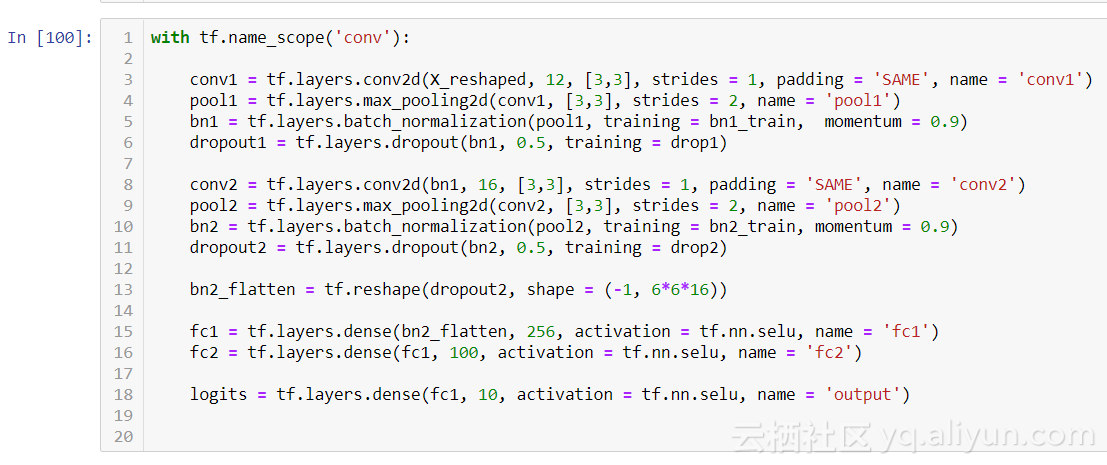
批量標(biāo)準(zhǔn)化只是簡單地對每批次的數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化。我們指定了 0.9 的動(dòng)量。而 dropout 和正則化指定動(dòng)量為 1 才能在訓(xùn)練期間完全隨機(jī)地關(guān)閉節(jié)點(diǎn)。這導(dǎo)致其余節(jié)點(diǎn)必須松弛,從而提高其有效性。想象一下,一家公司決定每周隨機(jī)選擇 50 名員工留在家里。其余的工作人員將不得不有效地處理額外的工作,提高他們在其他領(lǐng)域的技能。
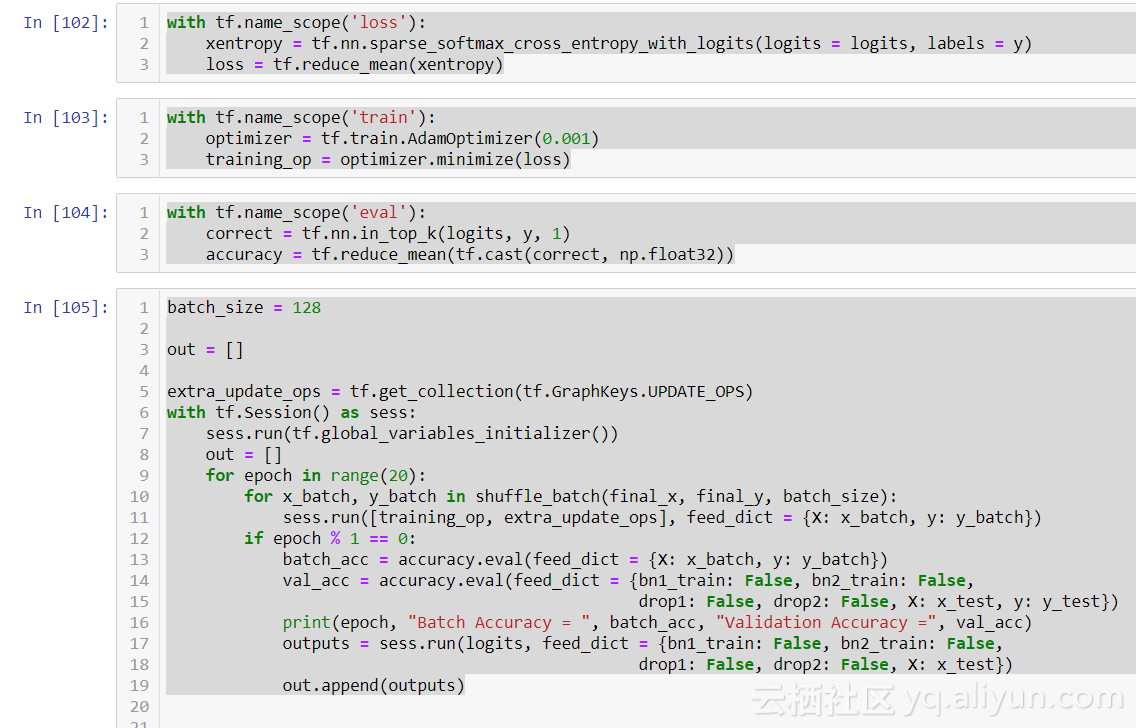
接著我們創(chuàng)建我們的損失函數(shù),訓(xùn)練步驟和評(píng)估步驟,然后對我們的執(zhí)行階段進(jìn)行一些修改。通過批量標(biāo)準(zhǔn)化執(zhí)行的計(jì)算在每次迭代期間保存為更新操作。為了訪問這些,我們分配一個(gè)變量 extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)。在我們的訓(xùn)練操作期間,我們將其作為列表項(xiàng)與 training_op 一起提供給 sess.run。最后,在執(zhí)行驗(yàn)證 / 測試預(yù)測時(shí),我們通過 feed_dict 為占位符分配 False 值。我們不希望在預(yù)測階段有任何隨機(jī)化。為了獲得輸出,我們使用我們的測試集運(yùn)行 logits 操作。讓我們看看這個(gè)模型添加正則化 / 標(biāo)準(zhǔn)化并且正在使用增強(qiáng)數(shù)據(jù)的方法后表現(xiàn)得如何。
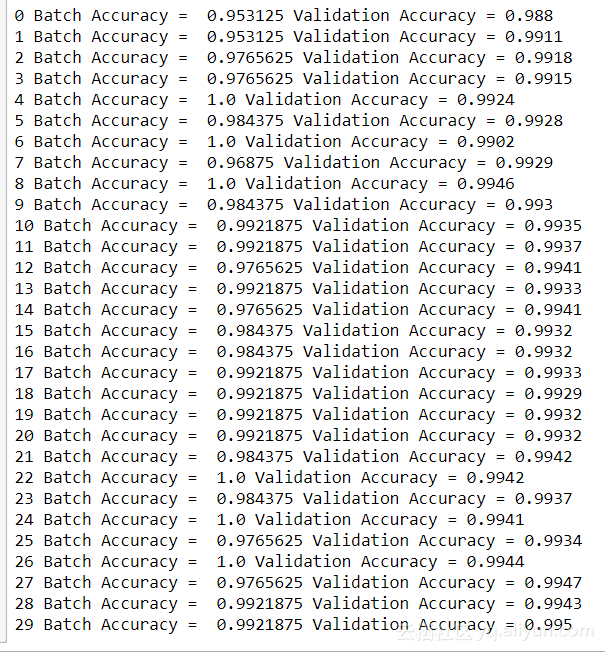
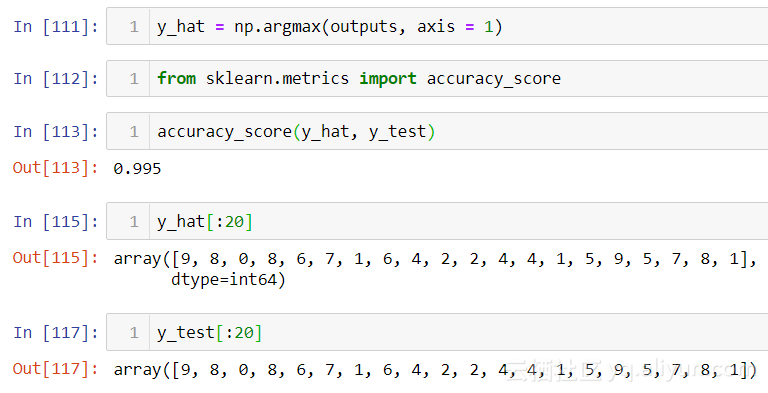
在 29epoch,我們在 10,000 個(gè)數(shù)字的測試集上達(dá)到了 99.5%的準(zhǔn)確率。正如你所看到的那樣,第二個(gè) epoch 時(shí)模型精確度達(dá)到了 99%,而之前的模型只有 16%。雖然 0.05%可能不是很多,但在處理大量數(shù)據(jù)時(shí)這是一個(gè)重大改進(jìn)。最后,我將向你展示如何在 logits 輸出上使用 np.argmax 產(chǎn)生的預(yù)測。
關(guān)于 Tensorflow 中 CNN 入門的手寫數(shù)字識(shí)別是怎樣的就分享到這里了,希望以上內(nèi)容可以對大家有一定的幫助,可以學(xué)到更多知識(shí)。如果覺得文章不錯(cuò),可以把它分享出去讓更多的人看到。











