共計 6531 個字符,預(yù)計需要花費(fèi) 17 分鐘才能閱讀完成。
自動寫代碼機(jī)器人,免費(fèi)開通
丸趣 TV 小編給大家分享一下 MySQL 查詢優(yōu)化的示例分析,希望大家閱讀完這篇文章之后都有所收獲,下面讓我們一起去探討吧!
一、優(yōu)化的思路和原則有哪些
1、優(yōu)化更需要優(yōu)化的查詢
2、定位優(yōu)化對象的性能瓶頸
3、明確優(yōu)化的目標(biāo)
4、從 Explain 入手
5、多使用 profile
6、永遠(yuǎn)用小結(jié)果集驅(qū)動大結(jié)果集
7、盡可能在索引中完成排序
8、只取出自己需要的字段(Columns)
9、僅僅使用最有效的過濾條件
10、盡可能避免復(fù)雜的 join
相關(guān)免費(fèi)學(xué)習(xí)推薦:mysql 視頻教程
1、優(yōu)化更需要優(yōu)化的查詢
?高并發(fā)的低消耗(相對)的查詢 對整個系統(tǒng)影響遠(yuǎn)大于低并發(fā)高消耗的查詢。
2、定位優(yōu)化對象的性能瓶頸
?在拿到一條需要優(yōu)化的查詢時,我們首先要判斷出這個查詢的瓶頸到底是 IO 還是 CPU。到底是數(shù)據(jù)庫訪問消耗多還是數(shù)據(jù)的運(yùn)算(如分組排序)消耗多。
3、明確優(yōu)化的目標(biāo)
?了解數(shù)據(jù)庫目前整體狀態(tài),就能知道數(shù)據(jù)庫所能承受的最大壓力,也就是我們知道最悲觀狀況;
?要把握該查詢相關(guān)的數(shù)據(jù)庫對象信息,我們就能知道最理想和最糟糕狀態(tài)下需要消耗多少資源;
?要知道該查詢在應(yīng)用系統(tǒng)中的地位,我們可以分析出改查詢可以占用系統(tǒng)資源的比例,也能夠知道該查詢的效率對客戶的體驗影響有多大。
4、從 Explain 入手
Explain 能夠告訴你這個查詢在數(shù)據(jù)庫中是一個什么樣的執(zhí)行計劃來實現(xiàn)的。首先我們需要有個目標(biāo),通過不斷調(diào)整嘗試,再借助 Explain 來驗證結(jié)果是否滿足自己的需求,直到得到預(yù)期的結(jié)果。
5、永遠(yuǎn)用小結(jié)果集驅(qū)動大結(jié)果集
?很多人喜歡在 SQL 優(yōu)化的時候說用“小表驅(qū)動大表”,這個說法是不嚴(yán)謹(jǐn)?shù)摹R驗榇蟊斫?jīng)過 where 條件過濾后返回的結(jié)果集并不一定就比小表所返回的結(jié)果集大,這個時候還用大表驅(qū)動小表,就會得到相反的性能效果。
?這樣的結(jié)果也非常容易理解,在 MySQL 中的 Join,只有 Nested Loop 一種 Join 方式,也就是 MySQL 的 Join 都是通過嵌套循環(huán)來實現(xiàn)的。驅(qū)動結(jié)果集越大,所需要循環(huán)的此時就越多,那么被驅(qū)動表的訪問次數(shù)自然也就越多,而每次訪問被驅(qū)動表,即使需要的邏輯 IO 很少,循環(huán)次數(shù)多了,總量自然也不可能很小,而且每次循環(huán)都不能避免的需要消耗 CPU,所以 CPU 運(yùn)算量也會跟著增加。所以,如果我們僅僅以表的大小來作為驅(qū)動表的判斷依據(jù),假若小表過濾后所剩下的結(jié)果集比大表多很多,結(jié)果就是需要的嵌套循環(huán)中帶來更多的循環(huán)次數(shù),反之,所需要的循環(huán)次數(shù)就會更少,總體 IO 量和 CPU 運(yùn)算量也會少。而且,就算是非 Nested Loop 的 Join 算法,如 Oracle 中的 Hash Join,同樣是小結(jié)果集驅(qū)動大的結(jié)果集是最優(yōu)的選擇。
?所以,在優(yōu)化 Join Query 的時候,最基本的原則就是“小結(jié)果集驅(qū)動大結(jié)果集”,通過這個原則來減少嵌套循環(huán)中的循環(huán)次數(shù),達(dá)到減少 IO 總量以及 CPU 運(yùn)算的次數(shù)。盡可能在索引中完成排序
6、只取出自己需要的字段(Columns)
?對于任何查詢,返回的數(shù)據(jù)都是需要通過網(wǎng)絡(luò)數(shù)據(jù)包傳輸給客戶端,如果取出的 Column 越多,需要傳輸?shù)臄?shù)據(jù)量自然會越大,不論從網(wǎng)絡(luò)帶寬還是網(wǎng)絡(luò)傳輸緩沖區(qū)來看,都是一種浪費(fèi)。
7、僅僅使用最有效的過濾條件
?舉個例子一個用戶表 user 有 id 和 nick_name 等字段,索引是 id 和 nike_name 兩個索引,下面是兩個查詢語句
#1
select * from user where id = 1 and nick_name = zs
selet * from user where id = 1?兩個查詢得到結(jié)果是一樣的,但是第一個語句用到的索引占用空間是比第二個語句大很多的。占用空間大也代表著要讀取的數(shù)據(jù)量也更多。,也就是說 2 的查詢語句才是最優(yōu)查詢。
8、避免復(fù)雜的 join 查詢
?我們的查詢語句所涉及到的表越多,所需要鎖定的資源就越多。也就是說,越復(fù)雜的 Join 語句,所需要鎖定的資源也就越多,所阻塞的其他線程也就越多。相反,如果我們將比較復(fù)雜的查詢語句分拆成多個較為簡單的查詢語句分步執(zhí)行,每次鎖定的資源也就會少很多,所阻塞的其他線程也要少一些。
?可能很多人會有疑問,將復(fù)雜 Join 語句分拆成多個簡單的查詢語句之后,那不是我們的網(wǎng)絡(luò)交互就會更多了嗎?網(wǎng)絡(luò)延時方面的總體消耗也就更大了啊,完成整個查詢的時間不是反而更長了嗎?是的,這種情況是可能存在,但也并不是肯定就會如此。我們可以再分析一下,一個復(fù)雜的查詢語句在執(zhí)行的時候,所需要鎖定的資源比較多,可能被別人阻塞的概率也就更大,如果是一個簡單的查詢,由于需要鎖定的資源較少,被阻塞的概率也會小很多。所以 較為復(fù)雜的連接查詢也有可能在執(zhí)行之前被阻塞而浪費(fèi)更多的時間。而且我們的數(shù)據(jù)庫所服務(wù)的并不是單單這一個查詢請求,還有很多很多其他的請求,在高并發(fā)的系統(tǒng)中,犧牲單個查詢的短暫響應(yīng)時間而提高整體處理能力也是非常值得的。優(yōu)化本身就是一門平衡與取舍的藝術(shù),只有懂得取舍,平衡整體,才能讓系統(tǒng)更優(yōu)。
二、利用 Explain 和 Profiling
1、Explain 使用
各種信息展示
字段說明 ID 執(zhí)行計劃中查詢的序列號 Select_type 查詢類型:
DEPENDENT SUBQUERY : 子查詢中內(nèi)層的第一個 SELECT, 依賴于外部查詢結(jié)果集;
DEPENDENT UNION:子查詢中的 UNION 中從第二個 SELECT 開始的后面所有 SELECT, 同樣依賴于外部查詢結(jié)果集;
PRIMARY: 子查詢中的最外層查詢,不是主鍵查詢;
SUBQUERY:子查詢內(nèi)層查詢的第一個 SELECT, 結(jié)果不依賴于外部結(jié)果集;
UNCACHEABLE SUBQUERY:結(jié)果集無法緩存的子查詢;
UNION:UNION 語句中第二個 SELECT 開始的后面所有 SELECT, 第一個 SELECT 為 PRIMARY
UNION RESULT:UNION 中的合并結(jié)果 Table 所訪問的數(shù)據(jù)庫中表名稱 TYPE 訪問方式:
ALL: 全表掃描
const: 常量,最多只有一條記錄匹配,由于是常量,所以實際上只需要讀一次
eq_ref: 最多只有一條匹配結(jié)果,一般是主鍵或者唯一索引來訪問的
index: 全索引掃描
range: 索引范圍掃描
ref: jion 語句中被驅(qū)動表索引的引用查詢
system: 系統(tǒng)表,表中只有一行數(shù)據(jù) Possible_keys 可能用到的索引 Key 使用的索引 Key_len 索引長度 Rows 估算出來的結(jié)果集記錄條數(shù) Extra 額外信息
2、Profiling 使用
該工具可以獲取一條 Query 在整個執(zhí)行過程中多種資源消耗情況,如 CPU,IO,IPC,SWAP 等,以及發(fā)生 PAGE FAULTS, CONTEXT SWITCHE 等等,同時還能得到該 Query 執(zhí)行過程中 MySQL 所調(diào)用的各個函數(shù)在源文件中的位置。
1、開啟 profiling 參數(shù) 1- 開啟,0- 關(guān)閉
# 開啟 profiling 參數(shù) 1- 開啟,0- 關(guān)閉 set profiling=1;SHOW VARIABLES LIKE %profiling%2、然后執(zhí)行一條 Query化的示例分析")
3、獲取系統(tǒng)保存的 profiling 信息
show PROFILES; 4、通過 QUERY_ID 獲取 profile 的詳細(xì)信息(下面以獲取 CPU 和 IO 為例)
4、通過 QUERY_ID 獲取 profile 的詳細(xì)信息(下面以獲取 CPU 和 IO 為例)
show profile cpu, block io for QUERY 7;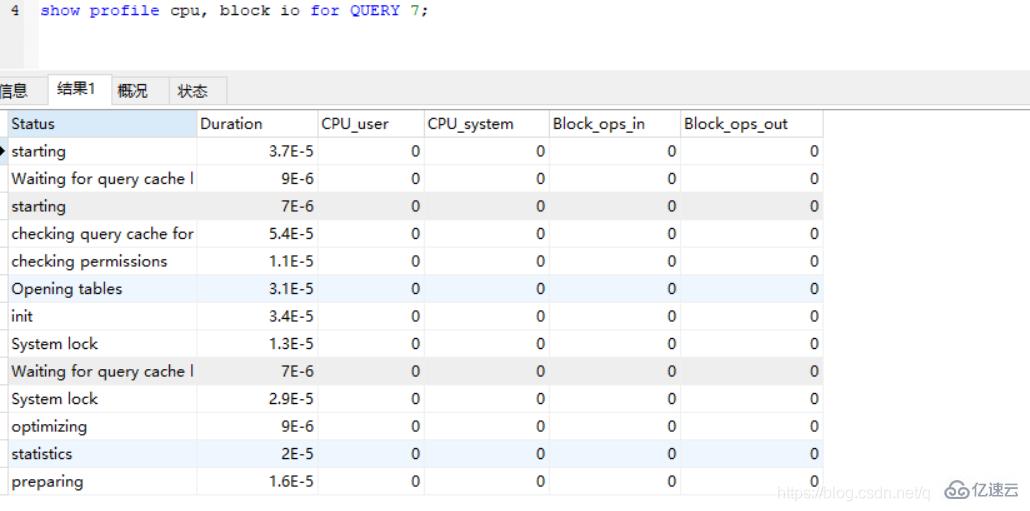
三、合理利用索引
1、什么是索引
?簡單來說,在關(guān)系型數(shù)據(jù)庫中,索引是一種單獨(dú)的,物理的對數(shù)據(jù)庫表中一列或者多列的值進(jìn)行排序的一種存儲結(jié)構(gòu)。就像書的目錄,可以根據(jù)目錄中的頁碼快速找到需要的內(nèi)容。
?在 MySQL 中主要有四種類型索引,分別是:B-Tree 索引,Hash 索引,F(xiàn)ullText 索引,R-Tree 索引,下面主要說一下我們常用的 B -Tree 索引,其他索引可以自行查找資料。
2、索引的數(shù)據(jù)結(jié)構(gòu)
?一般來說,MySQL 中的 B -Tree 索引的物理文件大多數(shù)都是以平衡樹的結(jié)構(gòu)來存儲的,也就是所有實際需要存儲的數(shù)據(jù)都存儲于樹的葉子節(jié)點,二到任何一個葉子節(jié)點的最短路徑的長度都是完全相同的。MySQL 中的存儲引擎也會稍作改造,比如 Innodb 存儲引擎的 B -Tree 索引實際上使用的存儲結(jié)構(gòu)是 B +Tree, 在每個葉子節(jié)點存儲了索引鍵相關(guān)信息之外,還存儲了指向相鄰的葉子節(jié)點的指針信息,這是為了加快檢索多個相鄰的葉子節(jié)點的效率。
?在 Innodb 中,存在兩種形式的索引,一種是聚簇形式的主鍵索引,另外一種形式是和其他存儲引擎(如 MyISAM)存放形式基本相同的普通 B -Tree 索引,這種索引在 Innodb 存儲引擎中被稱作二級索引。化的示例分析")
?圖示中左邊為 Clustered 形式存放的 Primary Key,右側(cè)則為普通的 B-Tree 索引。兩種索引在根節(jié)點和 分支節(jié)點方面都還是完全一樣的。而 葉子節(jié)點就出現(xiàn)差異了。在主鍵索引中,葉子結(jié)點存放的是表的實際數(shù)據(jù),不僅僅包括主鍵字段的數(shù)據(jù),還包括其他字段的數(shù)據(jù),整個數(shù)據(jù)以主鍵值有序的排列。而二級索引則和其他普通的 B-Tree 索引沒有太大的差異,只是在葉子結(jié)點除了存放索引鍵的相關(guān)信息外,還存放了 Innodb 的主鍵值。
?所以,在 Innodb 中如果通過主鍵來訪問數(shù)據(jù)效率是非常高的,而如果是通過二級索引來訪問數(shù)據(jù)的話,Innodb 首先通過二級索引的相關(guān)信息,通過相應(yīng)的索引鍵檢索到葉子節(jié)點之后,需要再通過葉子節(jié)點中存放的主鍵值再通過主鍵索引來獲取相應(yīng)的數(shù)據(jù)行。
?MyISAM 存儲引擎的主鍵索引和非主鍵索引差別很小,只不過是主鍵索引的索引鍵是一個唯一且非空的鍵而已。而且 MyISAM 存儲引擎的索引和 Innodb 的二級索引的存儲結(jié)構(gòu)也基本相同,主要的區(qū)別只是 MyISAM 存儲引擎在葉子節(jié)點上面除了存放索引鍵信息之外,再存放能直接定位 MyISAM 數(shù)據(jù)文件中相應(yīng)的數(shù)據(jù)行的信息(如 Row Number),但并不會存放主鍵的鍵值信息。
3、索引的利弊
優(yōu)點:提高數(shù)據(jù)的檢索速度,降低數(shù)據(jù)庫的 IO 成本;
缺點:查詢需要更新索引信息帶來額外的資源消耗,索引還會占用額外的存儲空間
4、如何判斷是否需要建立索引
?上面說了索引的利弊,我們知道索引并不是越多越好,索引也會帶來副作用。那么我們該怎么判斷是否需要建立索引呢?
1、較頻繁的作為查詢條件的字段應(yīng)該創(chuàng)建索引;
2、更新頻繁的字段不適合建立索引;
3、唯一性太差的不適合創(chuàng)建索引,如狀態(tài)字段;
4、不出現(xiàn)在 where 中的字段不適合創(chuàng)建索引;
5、單索引還是組合索引?
?在一般的應(yīng)用場景,只要不是其中某個過濾字段在大多數(shù)場景下都能過濾 90% 以上的數(shù)據(jù),而且其他的過濾字段會頻繁更新,我一般更傾向于創(chuàng)建組合索引,尤其是在并發(fā)量較高的場景下更是如此。因為并發(fā)量搞的時候,即使我們?yōu)槊總€查詢節(jié)省很少 IO 消耗,但因為執(zhí)行量非常大,所節(jié)省的資源總量還是很大的。
?但是我們創(chuàng)建組合索引并不是說查詢條件中的所有字段都要放在一個索引中,我們應(yīng)該讓一個索引被多個查詢所利用,盡量減少索引的數(shù)量,以此來減少更新的成本和存儲成本。
?MySQL 為我們提供了一個減少優(yōu)化索引自身的功能,那就是“前綴索引”。也就是我們可以僅僅使用某個字段的前面部分內(nèi)容作為索引鍵來索引該字段, 減少索引所占用的空間和提高索引的訪問效率。當(dāng)然前綴索引只適合前綴比較隨機(jī)重復(fù)很少的字段。
6、索引的選擇
1、對于單鍵索引,盡量針對當(dāng)前查詢過濾最好的索引;
2、在選擇組合索引的時候,當(dāng)前查詢中過濾性最好的字段在索引字段順序中排列越靠前越好;
3、在選擇組合索引的時候,盡量選擇可以能夠包含當(dāng)前查詢的 where 字句中更多字段的索引;
4、盡可能通過分析統(tǒng)計信息和調(diào)整查詢的寫法來達(dá)到選擇合適的的索引來減少通過人為 Hint 控制索引的選擇,以為這樣后期維護(hù)成本會很高。
7、MySQL 索引的限制
1、MyISAM 存儲引擎索引鍵長總和不能超過 1000 字節(jié);
2、BLOB 和 TEXT 類型字段只能創(chuàng)建前綴索引;
3、MySQL 不支持函數(shù)索引;
4、使用 != 或者 時候,MySQL 索引無法使用;
5、過濾字段使用函數(shù)運(yùn)算后,MySQL 索引無法使用;
6、jion 語句中近字段類型不一致的時候,MySQL 索引無法使用;
7、使用 like 如果是前匹配(如:’%aaa’),MySQL 索引無法使用;
8、使用非等值查詢的時候,MySQL 無法使用 HASH 索引;
9、字符類型是數(shù)字的時候要使用 =‘1’不可以直接使用 = 1;
10、不要使用 or 可以用 in 代替或者 union all;
8、Join 原理以及優(yōu)化
Join 原理:在 MySQL 中,只有一種 join 算法,就是大名鼎鼎的嵌套循環(huán),實際上就是通過驅(qū)動表的結(jié)果集作為循環(huán)基礎(chǔ)數(shù)據(jù),然后一條一條的通過該結(jié)果集中的數(shù)據(jù)作為過濾條件到下一個表中查詢數(shù)據(jù),然后合并結(jié)果。如果還有近參與,再通過前面的近結(jié)果集作為循環(huán)基礎(chǔ)數(shù)據(jù),再循環(huán)遍歷,如此往復(fù)。
優(yōu)化:
1、盡可能減少 Join 語句中的循環(huán)總次數(shù)(還記得前面說過的小結(jié)果集驅(qū)動大結(jié)果集嗎);
2、優(yōu)先優(yōu)化內(nèi)層循環(huán);
3、保證 Join 語句中被驅(qū)動表上的 Join 條件字段已經(jīng)被索引;
4、當(dāng)無法保證被驅(qū)動表的 Join 條件字段被索引且內(nèi)存資源充足條件下,不要吝嗇 Join buffer 的設(shè)置(join buffer 只會在 All,index,range 才能夠用的上);
9、ORDER BY 優(yōu)化
在 MySQL 中,ORDER BY 的實現(xiàn)只有兩種類型:
?1、通過有序的索引直接取得有序的數(shù)據(jù),這樣不用進(jìn)行任何排序操作即可得到客戶端要求的有序數(shù)據(jù);
?2、通過 MySQL 排序算法將存儲的引擎中返回的數(shù)據(jù)進(jìn)行排序然后再將排序后的數(shù)據(jù)返回給客戶端。
利用索引排序是最佳的方法,但是如果沒有索引林勇的時候,MySQL 主要兩種算法實現(xiàn):
?1、取出滿足過濾條件的用于排序條件的字段以及可以直接定位到行數(shù)據(jù)的行指針信息,在 Sort Buffer 中進(jìn)行實際的排序操作,然后利用排好序之后的數(shù)據(jù)根據(jù)行指針信息返回表中取得客戶端請求的其他字段的數(shù)據(jù),再返回給客戶端;
?2、根據(jù)過濾條件一次取出排序字段以及客戶端請求的所有其他字段的數(shù)據(jù),并將不需要排序的字段存放在一塊內(nèi)存區(qū)域中,然后在 Sort Buffer 中將排序字段和行指針信息進(jìn)行排序,最后再利用排序后的行指針與存放在內(nèi)存區(qū)域中和其他字段一起的行指針信息進(jìn)行匹配合并結(jié)果集,再按照順序返回給客戶端。
?第二種算法相較于第一種算法,主要就是減少了數(shù)據(jù)的二次訪問。在排序好后,不需要再次回到表中取數(shù)據(jù),節(jié)省了 IO 操作。當(dāng)然第二種算法會消耗更多的內(nèi)存,一種典型的以空間換取時間的優(yōu)化方式。
?對于多表 Join 排序是先通過一個臨時表將之前 Join 的結(jié)果集存放入臨時表之后再將臨時表的數(shù)據(jù)取到 Sort Buffer 中進(jìn)行操作。
對于非索引排序的時候,盡量選擇第二種算法來進(jìn)行排序,手段有:
?1、加大 max_length_for_sort_data 參數(shù)設(shè)置:
?MySQL 決定使用哪個算法是通過參數(shù) max_length_for_sort_data 來決定的,當(dāng)我們返回字段的最大長度小于這個參數(shù)時候,MySQL 就會選擇第二中算法,相反則第一種算法。所以在有充足內(nèi)存情況下,加大這個參數(shù)值可以讓 MySQL 選擇第二種算法;
?2、減少不必要的返回字段
?上面一樣的道理,字段少了,就會盡量小于 max_length_for_sort_data 參數(shù);
?3、增大 sort_buffer_size 參數(shù)設(shè)置:
?增大 sort_buffer_size 并不是為了讓 MySQL 可以選擇改進(jìn)版的排序算法,而是為了讓 MySQL 可以盡量減少在排序過程中對需要排序的數(shù)據(jù)進(jìn)行分段,因為這樣會造成 MySQL 不得不使用臨時表來進(jìn)行交換排序。
四、最后
?調(diào)優(yōu)其實是件很難的事情,調(diào)優(yōu)也不限于上面的查詢調(diào)優(yōu)。諸如表的設(shè)計優(yōu)化,數(shù)據(jù)庫參數(shù)的調(diào)優(yōu),應(yīng)用程序調(diào)優(yōu)(減少循環(huán)操作數(shù)據(jù)庫,批量新增;數(shù)據(jù)庫連接池;緩存;)等等。當(dāng)然還有很多調(diào)優(yōu)技巧只有在實際實踐中才能真正體會。只有自己以理論為基礎(chǔ),事實為依據(jù),不斷嘗試去提升自己,才能成為一個真正的調(diào)優(yōu)高手。
看完了這篇文章,相信你對“MySQL 查詢優(yōu)化的示例分析”有了一定的了解,如果想了解更多相關(guān)知識,歡迎關(guān)注丸趣 TV 行業(yè)資訊頻道,感謝各位的閱讀!
向 AI 問一下細(xì)節(jié)










