共計 2986 個字符,預計需要花費 8 分鐘才能閱讀完成。
本篇文章為大家展示了 RPC 框架 Dubbo 中非阻塞通信下的同步 API 實現原理是什么,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
Netty 在 Java NIO 領域基本算是獨占鰲頭,涉及到高性能網絡通信,基本都會以 Netty 為底層通信框架,Dubbo 也不例外。以下將以 Dubbo 實現為例介紹其是如何在 NIO 非阻塞通信基礎上實現同步通信的。
Dubbo 為一種 RPC 通信框架,提供進程間的通信,在使用 dubbo 協議 +Netty 作為傳輸層時,提供三種 API 調用方式:
同步接口
異步帶回調接口
異步不帶回調接口
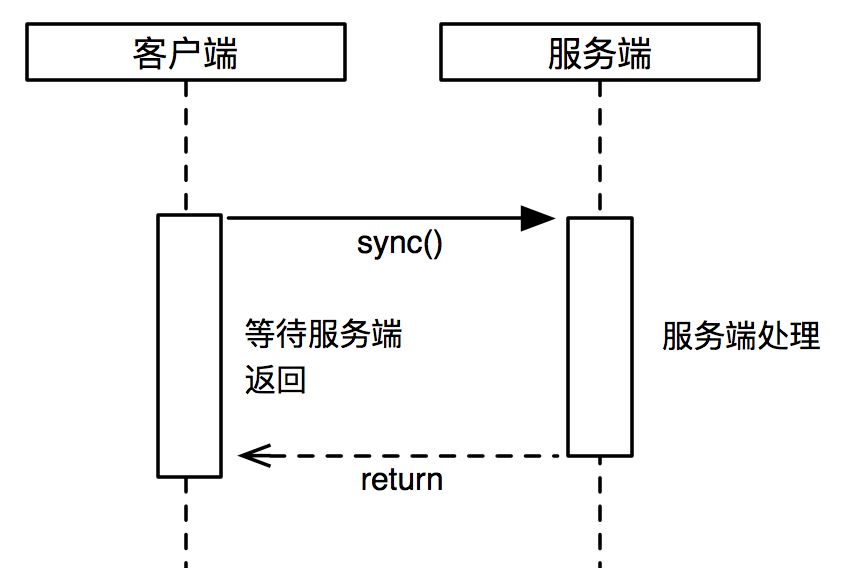
同步接口適用在大部分環境,通信方式簡單、可靠,客戶端發起調用,等待服務端處理,調用結果同步返回。這種方式下,在高吞吐、高性能(響應時間很快)的服務接口場景中最為適用,可以減少異步帶來的額外的消耗,也方便客戶端做一致性保證。
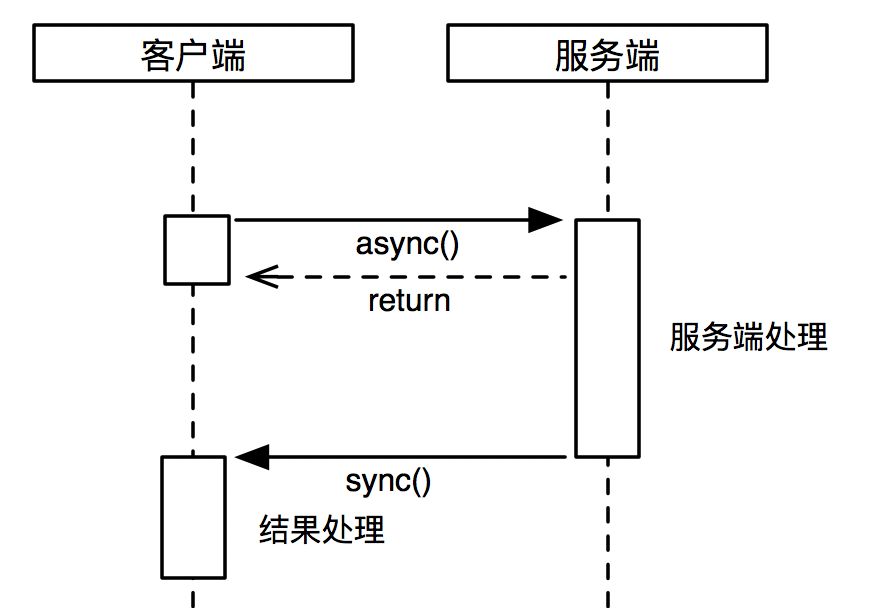
異步帶回調接口,用在任務處理時間較長,客戶端應用線程不愿阻塞等待,而是為了提高自身處理能力希望服務端處理完成后可以異步通知應用線程。這種方式可以大大提升客戶端的吞吐量,避免因為服務端的耗時問題拖死客戶端。
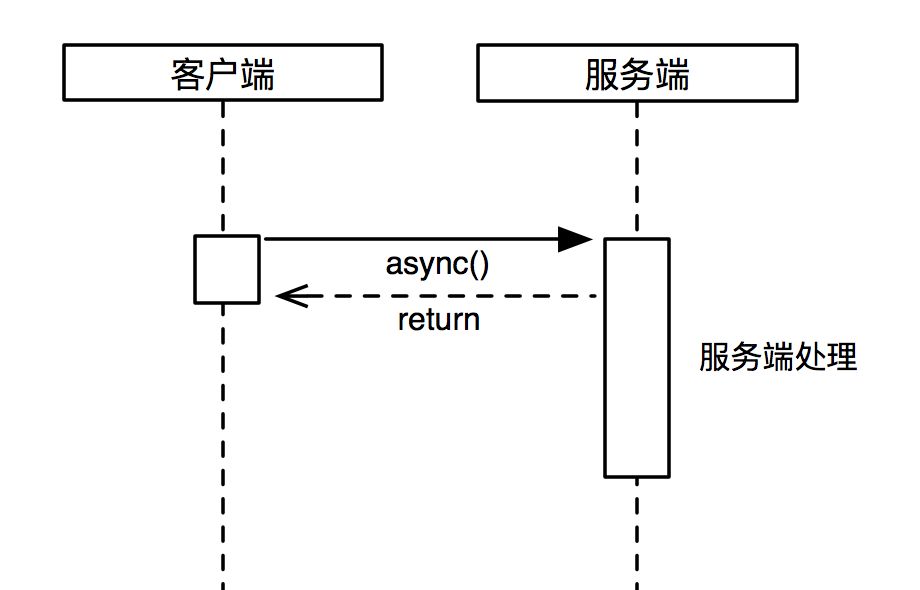
異步不帶回調接口,一些場景為了進一步提升客戶端的吞吐能力,只需發起一次服務端調用,不需關系調用結果,可以使用此種通信方式。一般在不需要嚴格保證數據一致性或者有其他補償措施的情況下,選用這種,可以最小化遠程調用帶來的性能損耗。
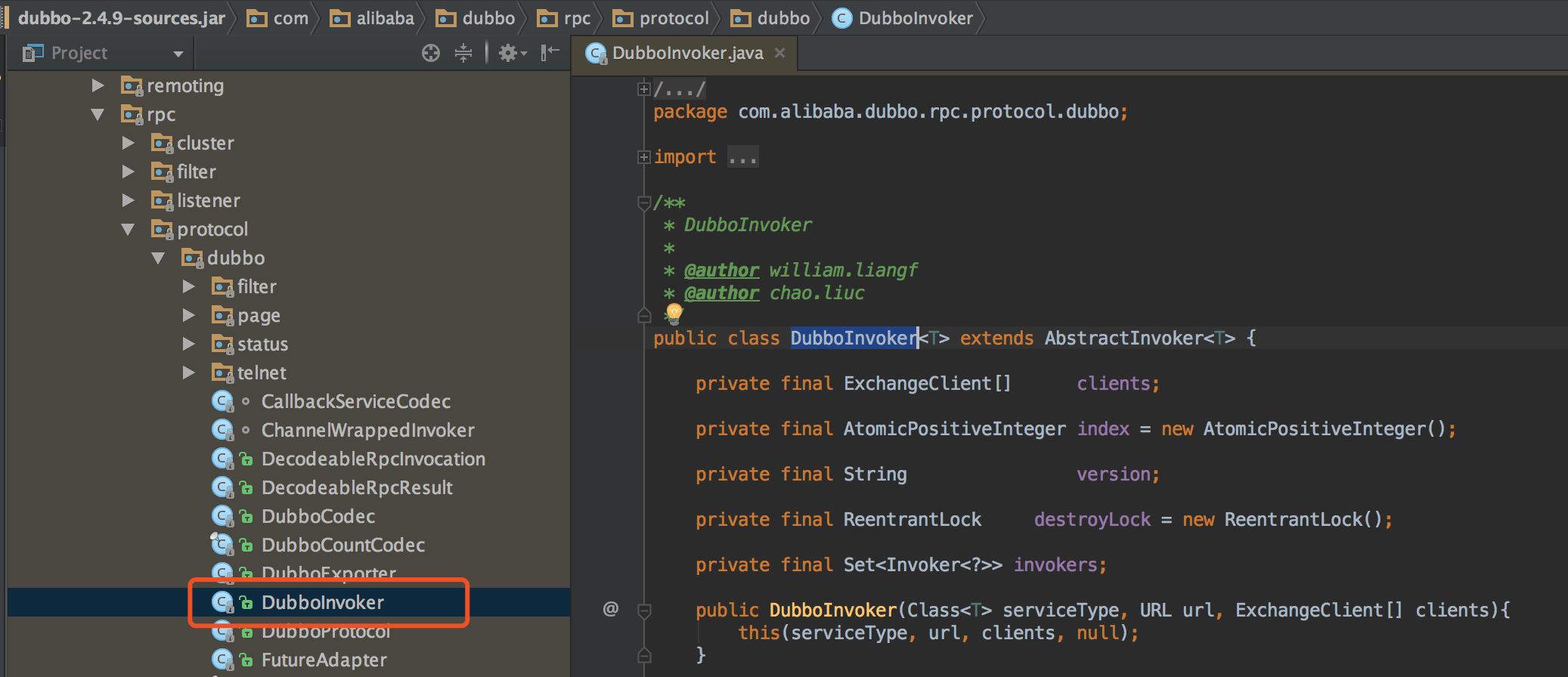
來看一下 Dubbo 是如何實現這三種 API 的。核心代碼在 com.alibaba.dubbo.rpc.protocol.dubbo.DubboInvoker,如下圖對應的位置,屬于協議層的實現部分。為方便大家可以準確定位代碼所在位置,使用截圖的方式,而不是直接貼代碼了。
上文描述的是三種 API 方式,Dubbo 里面通過參數 isOneway、isAsync 來控制,isOneway=true 表示異步不帶回調,isAsync=true 表示異步帶回調,否則是同步 API。具體是如何控制,看以下代碼:
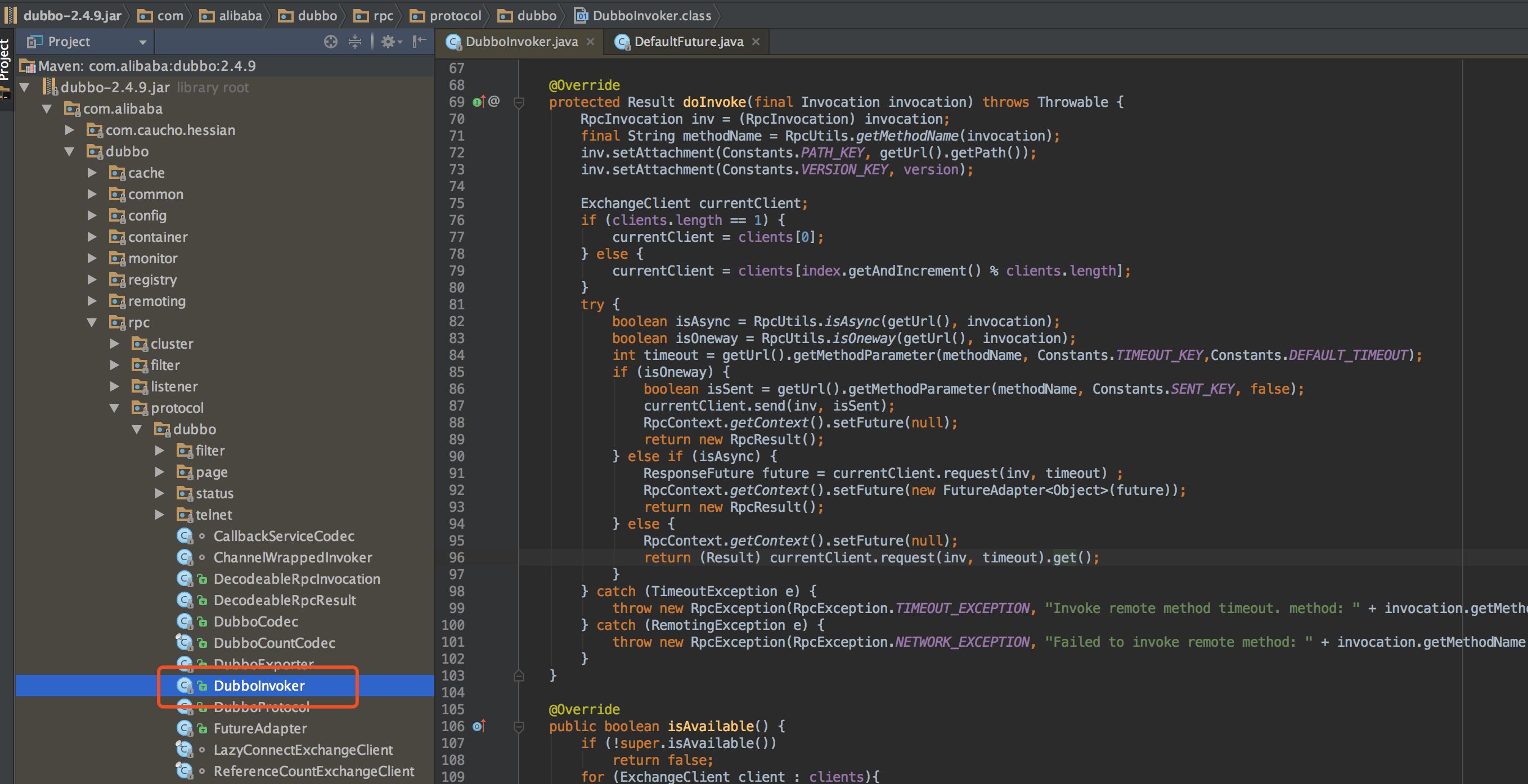
isOneway==true 時,客戶端 send 完請求后,直接 return 一個空結果的 RpcResult;isAsync==true 時,客戶端發起請求,設置一個 ResponseFuture,直接 return 一個空結果的 RpcResult,接下來當服務端處理完成,客戶端 Netty 層在收到響應后會通過 Future 通知應用線程;最后是同步情況下,客戶端發起請求,并通過 get() 方法阻塞等待服務端的響應結果。
異步 API 情況下,結合 NIO 模型比較好理解是如何實現的(當然需要先了解 NIO 的 reactor 模型),接下來重點理解下,這個 get() 阻塞方法是如何做到基于非阻塞 NIO 實現同步阻塞效果。
直接進入 get() 方法內部。
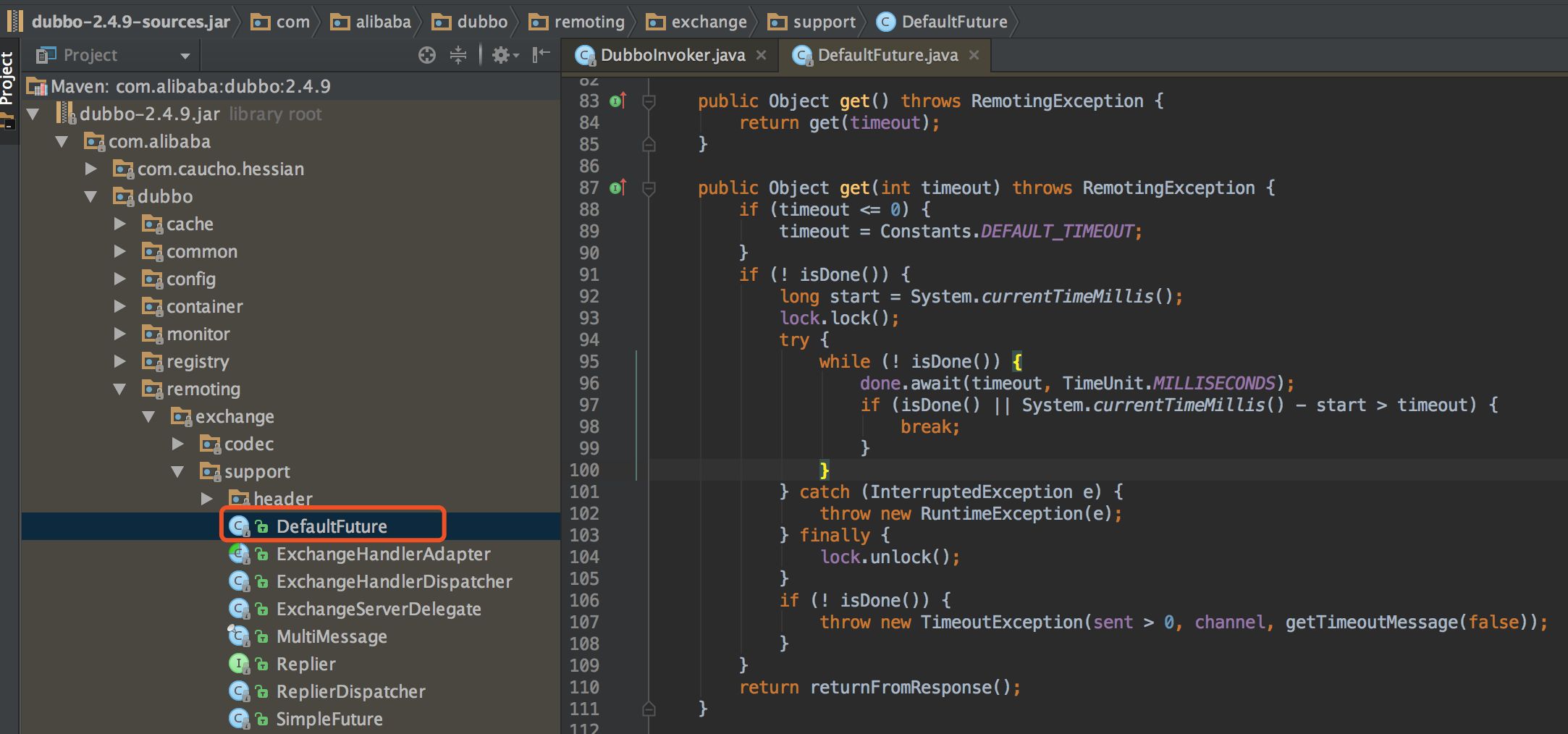
可以看到是利用 Java 的鎖機制實現,循環判斷是否收到響應,如果收到或者等待超時則返回。done 的實例對象如下:
private final Lock lock = new ReentrantLock();private final Condition done = lock.newCondition();使用可重入鎖 ReentrantLock,獲取一個 Condition 對象在其上做 await 操作。這里有 await 操作,何時被喚醒呢,有兩個條件,第一個是等待 timeout 超時,默認 dubbo 是 1s,第二個就是被其他線程喚醒,即收到了服務端的響應。

signal 信號一發出,上文循環檢測內的 await 操作會立即返回,下一次 isDone 判斷會變成 true,直接跳出循環。
仔細看代碼會發現,被喚醒的地方還有一個是在 DefaultFuture 內部有一個超時輪詢檢測的線程,這個線程主要是處理響應超時后觸發資源回收、記錄異常日志等操作。
private static class RemotingInvocationTimeoutScan implements Runnable { public void run() { while (true) {
try { for (DefaultFuture future : FUTURES.values()) { if (future == null || future.isDone()) {
continue;
}
if (System.currentTimeMillis() - future.getStartTimestamp() future.getTimeout()) {
// create exception response.
Response timeoutResponse = new Response(future.getId());
// set timeout status.
timeoutResponse.setStatus(future.isSent() ? Response.SERVER_TIMEOUT : Response.CLIENT_TIMEOUT);
timeoutResponse.setErrorMessage(future.getTimeoutMessage(true));
// handle response.
DefaultFuture.received(future.getChannel(), timeoutResponse);
}
}
Thread.sleep(30);
} catch (Throwable e) { logger.error( Exception when scan the timeout invocation of remoting. , e);
}
}
}
}
static { Thread th = new Thread(new RemotingInvocationTimeoutScan(), DubboResponseTimeoutScanTimer
th.setDaemon(true);
th.start();
}
可能會有疑問,這個觸發操作為何不直接在 get() 方法內部檢測到超時直接調用 DefaultFuture.received(Channel channel, Response response) 來清理,而是要額外開啟一個后臺線程。
單獨啟動一個超時線程有兩個好處:
提高超時精度
get() 方法內部的輪詢有一個 timeout,每次超時喚醒的時間間隔至少是 timeout 時長,最差的情況可能會等待 2 *timeout 作出超時反應。在超時輪詢線程中,每隔 30ms 遍歷檢測一次,可以很大程度的提升超時精度。
2. 提升性能,降低響應時間
剝離超時處理邏輯到一個單獨線程,可以減少對業務線程的時間占用,這個超時后的處理對應用來說并無直接作用,完全可以放到后臺異步去處理。另外單獨在一個線程中,實際上有批量處理的表現。
以上是就 NIO 通信基礎上實現三種 API 調用的實現原理,或許有更多優于 Dubbo 的處理方式,可以拿出來討論。
上述內容就是 RPC 框架 Dubbo 中非阻塞通信下的同步 API 實現原理是什么,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注丸趣 TV 行業資訊頻道。











