共計 3316 個字符,預計需要花費 9 分鐘才能閱讀完成。
如何實現 Kubernetes 可觀察性監測,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
我們將向您展示如何完成基本的 Kubernetes 可觀察性任務: 從運行在 Kubernetes 集群上的應用程序獲得黃金指標或黃金信號。我們不需要修改任何代碼,也不需要進行任何配置,只要安裝 Linkerd(一個開源的超輕服務網格) 就可以做到這一點。我們將介紹什么是服務網格,術語可觀察性是什么意思,以及這兩者在 Kubernetes 上下文中是如何關聯的。
用服務網格監控 Kubernetes 應用程序
如果你們剛剛適應了 Kubernetes。恭喜你! 但是現在你需要干什么? 任何 Kubernetes 使用者者的第一個可觀察性任務之一是監視,您需要知道什么時候出現了問題,以便您可以快速地修復它們。
Kubernetes 可觀察性是一個非常廣泛的話題,網上有很多關于可觀察性與監控、分布式跟蹤與日志記錄等之間的細微差別的討論。在本文中,我們將重點討論一個基本問題: 在不更改任何代碼的情況下,從運行在集群上的應用程序獲得黃金指標或黃金信號。我們將安裝一個 Linkerd,一個開源的超輕量級服務網格。與大多數服務網格不同,Linkerd 只需要在集群上安裝幾分鐘,不需要配置。
雖然簡單,但 Linkerd 包含了一個非常強大的度量管道。一旦安裝完畢,它將通過觀察集群上運行的所有組件之間的 HTTP(或 gRPC) 和 TCP 通信,自動檢測并報告成功率、流量級別和響應延遲。
linkd 可以自動為服務報告度量標準通常被引用為服務的黃金度量標準。
什么是黃金度量標準? 為什么它們很重要?
如果您已經知道黃金參數是什么,請跳過這一節!
黃金指標或黃金信號是您需要了解應用程序是否按預期啟動和運行的首要指標。這些度量為您提供了有關服務運行狀況的粗略信號,而不需要知道服務的實際功能。
Cindy Sridharan 在她的關于監控和可觀察性的博文中寫道: 當不直接驅動報警時,監控數據應該被優化,以提供系統整體健康狀況的鳥瞰圖。
谷歌 SRE 書定義的黃金指標為:
延遲——一種衡量服務速度快慢的方法。它是服務請求所花費的時間,通常以百分比來度量。第 99 百分位延遲為 5ms 意味著 99% 的請求在 5ms 或更短的時間內得到服務。流量——讓你知道某項服務有多忙或需求有多復雜。通常用每秒對服務的請求數來衡量。錯誤 - 請求失敗的數量。通常與總流量相結合來生成一個成功率——成功請求與遇到錯誤請求的比率。飽和 - 衡量你的系統的負載
通過觀察服務的流量,Linkerd 可以簡單地提供延遲、流量和錯誤的測量——樂觀地說,Linkerd 以成功率的形式提供了這些數據。(第四個指標,飽和度,在監控討論中經常被忽略,因為它需要了解服務的內部情況,通常跟蹤其他指標,如流量和延遲。)
有時這些指標也被稱為服務的 RED 指標:
Rate——您的服務每秒正在處理的請求數。Errors—每秒失敗的請求數。Duration——每個請求所花費時間的分布
不管你怎么稱呼它們,Linkerd 的美妙之處在于,它不僅記錄這些指標的流量,而且匯總和報告它們,這樣我們就可以輕松地使用它們。(我們將在下面看到。) 這使我們能夠監控我們的應用程序。一旦我們能夠監控我們的應用程序,我們就可以在出錯時收到報警; 研究其長期性能; 并對其可靠性和性能進行測試和改進。
黃金指標: 最簡單的方法 安裝: 訪問 Kubernetes 集群并安裝 Linkerd CLI
我們假設您有一個正常運行的 Kubernetes 集群和一個指向它的 kubectl 命令。在本節中,我們將帶您瀏覽 linkd 入門指南的縮寫版本,以便在這個集群上安裝 Linkerd 和一個演示應用程序 (我們將獲得最佳指標的應用程序)。
首先,安裝 Linkerd 命令行 (或者,直接從 Linkerd release 頁面下載。):
curl -sL https://run.linkerd.io/install | sh
export PATH=$PATH:$HOME/.linkerd2/bin
驗證 Kubernetes 集群是否能夠處理 linkd; 安裝 Linkerd; 并驗證安裝:
linkerd check --pre
linkerd install | kubectl apply -f -
linkerd check
最后,安裝 Emojivoto 演示應用程序,這是我們希望獲得黃金指標的應用程序。如果仔細觀察下面的命令,您將看到我們實際上是在向應用程序添加 linkerd(我們稱之為注入),然后將應用程序部署到 Kubernetes。(如果您想知道這是如何工作的,請查看我們的文檔 https://linkerd.io/2/tasks/adding-your-service/)。
curl -sL https://run.linkerd.io/emojivoto.yml \
| linkerd inject - \
| kubectl apply -f -
嗯,就是這樣。這就是您需要的所有工具,您的應用程序,并能夠訪問您的黃金指標! 現在讓我們來看看他們。
在 Grafana 查看度量
想要看到所有這些有用的圖表和儀表板嗎? 沒有問題! 運行 linkd dashboard -show grafana 并打開命令輸出的鏈接。您將看到 Linkerd 的頂層儀表盤,其中包含它所收集的指標的總體和每個名稱空間的細分。向下滾動到我們應用程序的命名空間 (ns/emojivoto),觀察以下圖表:
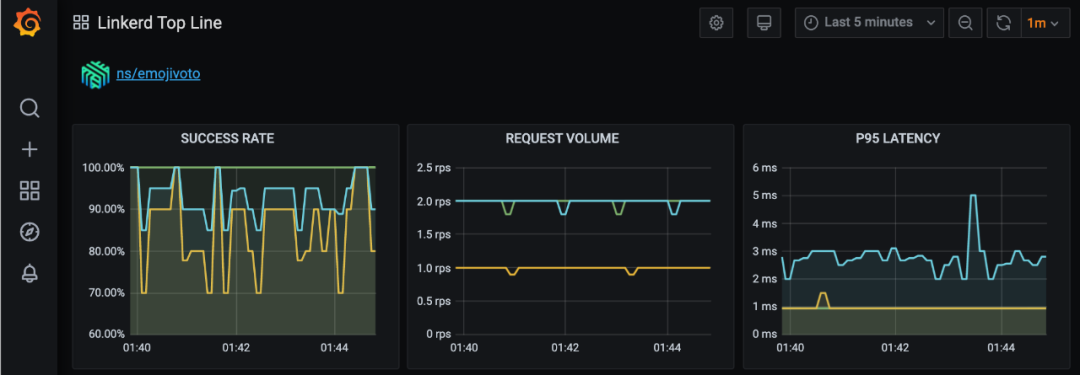
通過 linkd CLI 查看指標
我們還可以使用 linkd stat 命令查看應用程序的指標。
所有這些數據也可以在 Linkerd s dashboard 中找到,你可以通過運行 Linkerd dashboard 來訪問:


看看 Grafana 圖表 (或 linkd 儀表盤),你可以立即看到 voting 服務做得不是很好 - 它的成功率相當低! 向我們的應用程序中添加黃金指標可以立即讓我們看到應用程序中可能出現的問題。
真的這么簡單嗎? 答案是肯定的! 我們所需要做的就是安裝 Linkerd 并將其注入到我們的應用程序中。在底層,當 linkd 被添加到一個服務時,它會自動檢測與服務的 pod 之間的任何 HTTP 和 gRPC 調用。由于它能夠解析這些協議,它可以記錄這些調用的響應類和延遲,并將它們聚合在一起,在這種情況下,將它們合并到一個名為 Prometheus 的時間序列數據庫的小型內部實例中。當您通過 Linkerd 的儀表板和 CLI 查看黃金指標時,Linkerd 會從這個內部的 Prometheus 實例中獲取它們,在不修改應用程序代碼的情況下為您提供所有這些指標。
Linkerd 還能做什么?
我們已經看到了如何使用 Linkerd 來獲得黃金指標,這是獲得系統可觀察性的第一步,也就是說,獲得復雜應用程序中正在發生的事情的高級視圖。但指標只是個開始。當您繼續您的監視和可觀察性旅程時,您一定會遇到另外兩個常用的工具: 日志和分布式鏈路跟蹤。
分布式跟蹤涉及到檢測應用程序,以便測量請求在服務中花費的時間長度。當我們的應用程序使用許多相互通信的微服務時,跟蹤是一個很好的工具,可以用來調試緩慢的請求,并找出哪個服務是瓶頸。Linkerd 可以幫助分布式跟蹤,盡管一個服務網格在分布式跟蹤方面做的不多。
類似于分布式跟蹤,Linkerd 也提供了一個強大的動態請求跟蹤工具 tap。tap 命令類似于用于微服務的 tcpdump: 它允許您查看發送到或來自特定服務的實時請求 (示例)。Tap 是在生產中調試 Kubernetes 服務的強大工具。
最后,應用程序日志當然是開發人員在懷疑某個特定進程不正常時首先要做的事情之一。當運行一個服務網格時,有時候查看網格內部發生了什么是很有用的。雖然 Linkerd 不能為你提供應用程序日志,但 Linkerd logs 命令提供了一種簡單的方法,至少可以查看 Linkerd 內部發生了什么。
關于如何實現 Kubernetes 可觀察性監測問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注丸趣 TV 行業資訊頻道了解更多相關知識。











