共計 4095 個字符,預計需要花費 11 分鐘才能閱讀完成。
怎樣進行 Java 線程池管理及分布式 Hadoop 調(diào)度框架搭建,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
Java 線程池管理及分布式 Hadoop 調(diào)度框架搭建。
平時的開發(fā)中線程是個少不了的東西,比如 tomcat 里的 servlet 就是線程,沒有線程我們?nèi)绾翁峁┒嘤脩粼L問呢?不過很多剛開始接觸線程的開發(fā)工程師卻在這個上面吃了不少苦頭。怎么做一套簡便的線程開發(fā)模式框架讓大家從單線程開發(fā)快速轉入多線程開發(fā),這確實是個比較難搞的工程。
那具體什么是線程呢?首先看看進程是什么,進程就是系統(tǒng)中執(zhí)行的一個程序,這個程序可以使用內(nèi)存、處理器、文件系統(tǒng)等相關資源。例如 QQ 軟件、Eclipse、Tomcat 等就是一個 exe 程序,運行啟動起來就是一個進程。為什么需要多線程?如果每個進程都是單獨處理一件事情不能多個任務同時處理,比如我們打開 qq 只能和一個人聊天,我們用 eclipse 開發(fā)代碼的時候不能編譯代碼,我們請求 tomcat 服務時只能服務一個用戶請求,那我想我們還在原始社會。多線程的目的就是讓一個進程能夠同時處理多件事情或者請求。比如現(xiàn)在我們使用的 QQ 軟件可以同時和多個人聊天,我們用 eclipse 開發(fā)代碼時還可以編譯代碼,tomcat 可以同時服務多個用戶請求。
線程這么多好處,怎么把單進程程序變成多線程程序呢?不同的語言有不同的實現(xiàn),這里說下 java 語言的實現(xiàn)多線程的兩種方式:擴展 java.lang.Thread 類、實現(xiàn) java.lang.Runnable 接口。
先看個例子,假設有 100 個數(shù)據(jù)需要分發(fā)并且計算。看下單線程的處理速度:
package thread;
import java.util.Vector;
public class OneMain {
public static void main(String[] args) throws InterruptedException {
Vector Integer list = new Vector Integer (100);
for (int i = 0; i 100; i++) {
list.add(i);
}
long start = System.currentTimeMillis();
while (list.size() 0) {
int val = list.remove(0);
Thread. sleep(100);// 模擬處理
System. out.println(val);
}
long end = System.currentTimeMillis();
System. out.println(消耗 + (end – start) + ms
}
// 消耗 10063 ms
}
再看一下多線程的處理速度,采用了 10 個線程分別處理:
[java] view plaincopy 在 CODE 上查看代碼片派生到我的代碼片
package thread;
import java.util.Vector;
import java.util.concurrent.CountDownLatch;
public class MultiThread extends Thread {
static Vector Integer list = new Vector Integer (100);
static CountDownLatch count = new CountDownLatch(10);
public void run() {
while (list.size() 0) {
try {
int val = list.remove(0);
System.out.println(val);
Thread.sleep(100);// 模擬處理
} catch (Exception e) {
// 可能數(shù)組越界,這個地方只是為了說明問題,忽略錯誤
}
}
count.countDown(); // 刪除成功減一
}
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i 100; i++) {
list.add(i);
}
long start = System.currentTimeMillis();
for (int i = 0; i i++) {
new MultiThread().start();
}
count.await();
long end = System.currentTimeMillis();
System.out.println(消耗 + (end – start) + ms
}
// 消耗 1001 ms
}
復制代碼
大家看到了線程的好處了吧!單線程需要 10S,10 個線程只需要 1S。充分利用了系統(tǒng)資源實現(xiàn)并行計算。也許這里會產(chǎn)生一個誤解,是不是增加的線程個數(shù)越多效率越高。線程越多處理性能越高這個是錯誤的,范式都要合適,過了就不好了。需要普及一下計算機硬件的一些知識。我們的 cpu 是個運算器,線程執(zhí)行就需要這個運算器來運行。不過這個資源只有一個,大家就會爭搶。一般通過以下幾種算法實現(xiàn)爭搶 cpu 的調(diào)度:
隊列方式,先來先服務。不管是什么任務來了都要按照隊列排隊先來后到。
時間片輪轉,這也是最古老的 cpu 調(diào)度算法。設定一個時間片,每個任務使用 cpu 的時間不能超過這個時間。如果超過了這個時間就把任務暫停保存狀態(tài),放到隊列尾部繼續(xù)等待執(zhí)行。
優(yōu)先級方式:給任務設定優(yōu)先級,有優(yōu)先級的先執(zhí)行,沒有優(yōu)先級的就等待執(zhí)行。
這三種算法都有優(yōu)缺點,實際操作系統(tǒng)是結合多種算法,保證優(yōu)先級的能夠先處理,但是也不能一直處理優(yōu)先級的任務。硬件方面為了提高效率也有多核 cpu、多線程 cpu 等解決方案。目前看得出來線程增多了會帶來 cpu 調(diào)度的負載增加,cpu 需要調(diào)度大量的線程,包括創(chuàng)建線程、銷毀線程、線程是否需要換出 cpu、是否需要分配到 cpu。這些都是需要消耗系統(tǒng)資源的,由此,我們需要一個機制來統(tǒng)一管理這一堆線程資源。線程池的理念提出解決了頻繁創(chuàng)建、銷毀線程的代價。線程池指預先創(chuàng)建好一定大小的線程等待隨時服務用戶的任務處理,不必等到用戶需要的時候再去創(chuàng)建。特別是在 java 開發(fā)中,盡量減少垃圾回收機制的消耗就要減少對象的頻繁創(chuàng)建和銷毀。
之前我們都是自己實現(xiàn)的線程池,不過隨之 jdk1.5 的推出,jdk 自帶了 java.util.concurrent 并發(fā)開發(fā)框架,解決了我們大部分線程池框架的重復工作。可以使用 Executors 來建立線程池,列出以下大概的,后面再介紹。
newCachedThreadPool 建立具有緩存功能線程池
newFixedThreadPool 建立固定數(shù)量的線程
newScheduledThreadPool 建立具有時間調(diào)度的線程
有了線程池后有以下幾個問題需要考慮:
線程怎么管理,比如新建任務線程。
線程如何停止、啟動。
線程除了 scheduled 模式的間隔時間定時外能否實現(xiàn)精確時間啟動。比如晚上 1 點啟動。
線程如何監(jiān)控,如果線程執(zhí)行過程中死掉了,異常終止我們怎么知道。
考慮到這幾點,我們需要把線程集中管理起來,用 java.util.concurrent 是做不到的。需要做以下幾點:
將線程和業(yè)務分離,業(yè)務的配置單獨做成一個表。
構建基于 concurrent 的線程調(diào)度框架,包括可以管理線程的狀態(tài)、停止線程的接口、線程存活心跳機制、線程異常日志記錄模塊。
構建靈活的 timer 組件,添加 quartz 定時組件實現(xiàn)精準定時系統(tǒng)。
和業(yè)務配置信息結合構建線程池任務調(diào)度系統(tǒng)。可以通過配置管理、添加線程任務、監(jiān)控、定時、管理等操作。
組件圖為:
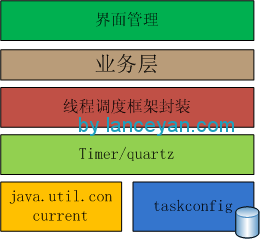
構建好線程調(diào)度框架是不是就可以應對大量計算的需求了呢? 答案是否定的。因為一個機器的資源是有限的,上面也提到了 cpu 是時間周期的,任務一多了也會排隊,就算增加 cpu,一個機器能承載的 cpu 也是有限的。所以需要把整個線程池框架做成分布式的任務調(diào)度框架才能應對橫向擴展,比如一個機器上的資源達到瓶頸了,馬上增加一臺機器部署調(diào)度框架和業(yè)務就可以增加計算能力了。好了,如何搭建?如下圖:度框架搭建")
基本前面的分布式調(diào)度框架組件不變,增加如下組件和功能:
改造分布式調(diào)度框架,可以把本身線程任務變成 mapreduce 任務并提交到 hadoop 集群。
hadoop 集群能夠調(diào)用業(yè)務接口的 spring、ibatis 處理業(yè)務邏輯訪問數(shù)據(jù)庫。
hadoop 需要的數(shù)據(jù)能夠通過 hive 查詢。
hadoop 可以訪問 hdfs/hbase 讀寫操作。
業(yè)務數(shù)據(jù)要及時加入 hive 倉庫。
hive 處理離線型數(shù)據(jù)、hbase 處理經(jīng)常更新的數(shù)據(jù)、hdfs 是 hive 和 hbase 的底層結構也可以存放常規(guī)文件。
這樣,整個改造基本完成。不過需要注意的是架構設計一定要減少開發(fā)程序的復雜度。這里雖然引入了 hadoop 模型,但是框架上開發(fā)者還是隱藏的。業(yè)務處理類既可以在單機模式下運行也可以在 hadoop 上運行,并且可以調(diào)用 spring、ibatis。減少了開發(fā)的學習成本,在實戰(zhàn)中慢慢體會就學會了一項新技能。
關于怎樣進行 Java 線程池管理及分布式 Hadoop 調(diào)度框架搭建 問題的解答就分享到這里了,希望以上內(nèi)容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注丸趣 TV 行業(yè)資訊頻道了解更多相關知識。











