共計 3433 個字符,預計需要花費 9 分鐘才能閱讀完成。
丸趣 TV 小編給大家分享一下怎么用 Rancher 創建產品質量數據庫設置,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
數據庫對業務至關重要,無論是數據丟失還是泄露,都會為企業帶來嚴重的風險。操作錯誤或體系結構故障都可能導致重大事件和資源的損失,這就需要故障轉移系統 / 過程來減少數據丟失的可能。在將數據庫體系結構遷移到 Kubernetes 之前,必須完成在容器體系結構以及裸機上運行數據庫集群的成本效益分析對比,這包括評估恢復時間目標(Recovery Time Objective,RTO)以及恢復數據目標(Recovery Point Objective,RPO)的災難恢復要求。這些分析在面對數據敏感的應用程序是非常重要,尤其當程序需要真正高可用、針對大規模和冗余需要地理分離、以及應用程序恢復要低延遲時。
在下文的步驟中,我們將分析在 Rancher 高可用和 Kubernetes 中可供使用的各種選項,給大家設計產品質量數據庫提供參考。
A.有狀態系統容器架構的缺點
部署在類似 Kubernetes 的集群中的容器自然是無狀態而且短暫的,這意味著它們不會保持固定的身份,并且當發生錯誤或重新啟動時會發生數據丟失和遺忘。在設計分布式數據庫環境時,需要提供高可用性以及容錯,這對 Kubernetes 的無狀態體系結構提出了挑戰,因為無論是復制還是擴展都需要維護下面的狀態:
(1)存儲;(2)身份;(3)會話;(4)集群角色。
考慮到我們的容器化應用程序,我們馬上就可以看出無狀態架構面臨的挑戰,我們的應用程序需要滿足一系列的要求:
我們的數據庫需要將數據(Data)和事務(Transactions)存儲在文件中,這些文件對每個數據庫容器來說都是持久且獨有的;
數據庫應用程序中的每個容器都需要維護一個固定的身份作為數據庫節點,以便我們可以通過名稱、地址或者索引將流量路由給它;
需要數據庫客戶端會話來維護狀態,為保證一致性,需確保在狀態更改之前,讀寫事務已經終止,而且出現持久性故障時狀態轉換不受影響。
個數據庫節點都需要在其數據庫集群中有持久化的角色,比如主機、副本或者分片,除非它們被特定的應用程序的事件更改,或者由于模式更改了而必須更改。
針對這些挑戰,目前的解決方案可能是將 PersistentVolume 附加到我們 Kubernetes pods 上,它的生命周期獨立于使用它的任何一個 pod。但是,PersistentVolume 不會向集群節點(即父節點、子節點或種子節點)提供一致的角色分配。集群不能保證在整個應用程序的生命周期中維護數據庫狀態,說的具體一點就是,新的容器會由非確定的隨機名稱創建,并且 pods 可以設置在任何時間按照任何的順序啟動、終止或者縮放。所以我們的挑戰依然存在。
B.K8s 部署分布式數據庫的優點
有這么多在 Kubernetes 集群中部署分布式數據庫的挑戰,我們是否還值得付出努力呢?Kubernetes 開辟了許多優勢和可能性,包括管理大量的數據庫服務以及常見的自動化操作,從可恢復性、可靠性和可擴展性來支持其生命周期健康。即使在虛擬化環境中,部署數據庫集群的所需的時間和成本也遠低于部署裸機集群。
Stateful Sets 提供了前一節中所述挑戰的前進方向。在 1.5 版本引入了 Stateful Sets 之后,Kubernetes 現在為存儲和身份實現了有狀態質量,保證了下面的內容:
每個 pod 都附有一個持久卷,從 pod 鏈接到存儲,這解決了 A 中的存儲狀態問題;
每個 pod 都以相同的順序開始并以相反的順序終止,這解決了 A 的會話狀態問題;
每個 pod 都有一個唯一且可確定的名稱、地址和序號索引,用于解決 A 中的身份和集群角色問題。
C.部署帶有 Headless 服務的有狀態集
注意:這部分我們會使用到 kubectl 服務。關于如何使用 Rancher 來部署 kubectl 服務可以參考這里:
https://rancher.com/docs/rancher/v2.x/en/k8s-in-rancher/kubectl/。
Stateful Set Pods 需要 headless 服務來管理 Pods 的網絡身份。實際上,headless 服務具有未定義的集群 IP 地址,這意味著在服務上沒有定義集群 IP。相反的,該服務定義具有選擇器,當服務被訪問的時候,DNS 被配置成返回多個地址記錄或者地址。此時,服務 fqdn 將使用相同的選擇器映射到服務后面的所有 pod IP 的所有 IP。
現在我們按照這個模板來為 Cassandra 創建一個 Headless 服務:

使用 get svc 命令列出 cassandra 服務的屬性:

用 describe svc 可以將 cassandra 服務的屬性按照 verbose 格式輸出:

D.為持久卷創建存儲類別
在 Rancher 中,通過本機的 Kubernetes API 資源、PersistentVolume 和 PersistentVolumeClaim,我們可以使用各種選項來管理持久存儲。Kubernetes 中的存儲類別告訴了我們哪些存儲類別是我們的集群所支持的。我們可以為持久存儲設置動態配置來自動創建卷,并將其附加到 pod。例如,下面的存儲類將 AWS 作為它的存儲提供者,使用類型是 gp2,可用區是 us-west-2a。

如果需要,還可以創建一個新的存儲類,例如:

在創建有狀態集時,將根據它的存儲類為有狀態集 pod 啟動 PersistentVolumeClaim。使用動態供應,可以根據 PersistentVolumeClaim 中請求的存儲類為 pod 動態供應 PersistentVolume。
您可也以通過靜態供應手動創建持久卷。可以在這里閱讀關于靜態供應的更多信息:
https://rancher.com/docs/rancher/v2.x/en/k8s-in-rancher/volumes-and-storage/。
注意:對于靜態供應,要求它具有與 Cassandra 服務器中的 Cassandra 節點數量相同的持久卷數量。
E.創建有狀態集
現在我們可以創建有狀態集,它將提供我們想要的屬性:有序的部署和終止、唯一的網絡名稱和有狀態的處理。我們調用下面命令,啟動一個 Cassandra 服務器:

F.驗證有狀態集
接著,我們調用下面命令驗證是否在 Cassandra 服務器中部署了有狀態集:

在創建了有狀態集之后,DESIRED 和 CURRENT 應該是相等的,調用 get pods 命令來查看經有狀態集創建的 pods 的順序列表。

在節點創建期間,你可以執行 nodetool state 來查看 Cassandra 節點是否啟動。

G.有狀態集的擴縮容
將 F 步驟中的設置復制 x 次,調用縮放命令就可以增加或者減少有狀態集的大小。在下面的示例中,我們按照 x = 3 進行操作。

調用 get statefulsets 可以驗證是否有狀態集已經部署到了 Cassandra 服務器上。

再次調用 get pods 來查看有狀態集創建的 pods 順序。需要注意的是,在部署 Cassandra pods 時,它們是按照順序創建的。

我們可以在 5 分鐘后執行 nodetool 狀態檢查,驗證 Cassandra 節點是否已經加入并且形成了一個 Cassandra 集群。
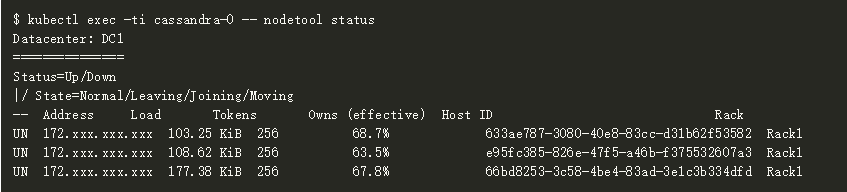
一旦 nodetool 中節點的狀態變更為 Up/Normal,我們就可以通過調用 CQL 來執行大量的數據庫操作。
H.調用 CQL 進行數據庫訪問和操作
當我們看到狀態是 U /N,我們就可以調用 cqlsh 來訪問 Cassandra 容器。

I.使用 Cassandra 作為高可用無狀態數據庫服務的持久層
在前面的練習中,我們在 K8s 集群中部署了一個 Cassandra 服務,并通過 PersistentVolume 提供持久存儲。然后,我們使用有狀態集為 Cassandra 集群提供有狀態處理的屬性,并將集群擴展到其他節點。我們現在可以在 Cassandra 集群中使用 CQL 模式進行數據庫訪問和操作。CQL 模式的優點是,我們可以輕松地使用自然類型和流暢的 api 實現無縫數據建模,特別是在設計擴展和時間序列數據模型(如欺詐檢測)的解決方案中。此外,CQL 利用分區和集群 keys 來提高數據建模場景中的操作速度。
以上是“怎么用 Rancher 創建產品質量數據庫設置”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注丸趣 TV 行業資訊頻道!











